A.2. Information-Gathering ToolsOn Unix systems, most information gathering tools are available straight from the command line. It is the same on Windows, provided Cygwin (http://www.cygwin.com) is installed. A.2.1. Online Tools at TechnicalInfoIf all you have is a browser, TechnicalInfo contains a set of links (http://www.technicalinfo.net/tools/) to various information-gathering tools hosted elsewhere. Using them can be cumbersome and slow, but they get the job done. A.2.2. NetcraftNetcraft (http://www.netcraft.co.uk) is famous for its "What is that site running?" service, which identifies web servers using the Server header. (This is not completely reliable since some sites hide or change this information, but many sites do not.) Netcraft is interesting not because it tells you which web server is running at the site, but because it keeps historical information around. In some cases, this information can reveal the real identity of the web server. This is exactly what happened with the web server hosting my web site www.modsecurity.org. I changed the web server signature some time ago, but the old signature still shows in Netcraft results. Figure A-3 reveals another problem with changing server signatures. It lists my server as running Linux and Internet Information Server simultaneously, which is implausible. In this case, I am using the signature "Microsoft-IIS/5.0" as a bit of fun. If I were to use it seriously, I would need to pay more attention to what signature I was choosing. Figure A-3. Historical server information from Netcraft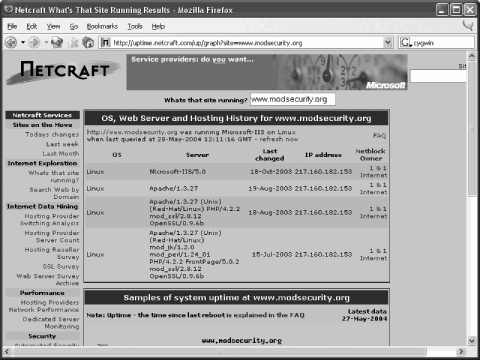 A.2.3. Sam SpadeSam Spade (http://www.samspade.org/ssw/), a freeware network query tool from Steve Atkins will probably provide you with all the network tools you need if your desktop is running Windows. Sam Spade includes all the passive tools you would expect, plus some advanced features on top of those:
Sam Spade's biggest asset comes from integration. It parses query results and understands what bits of information mean, allowing further actions to be performed quickly via a right-click context menu. Figure A-4 shows output from a whois query. Some queries are semi-automated; Sam will automatically perform further queries as you would typically want them done anyway. To save time, queries are performed in parallel where possible. Figure A-4. Sam Spade results of a whois query for www.oreilly.com Automatic activity logging is a big plus. Each query has its own window, but with a single click, you can choose whether to log its output. The Sam Spade web site contains a large library (http://www.samspade.org/d/) of document links. It can help to form a deeper understanding of the network and the way network query tools work. A.2.4. SiteDiggerSiteDigger (http://www.foundstone.com/resources/proddesc/sitedigger.htm and shown in Figure A-5) is a free tool from Foundstone (http://www.foundstone.com) that uses the Google API to automate search engine information gathering. (Refer to Chapter 11 for a discussion on the subject of using search engines for reconnaissance.) In its first release, it performs a set of searches using a predefined set of signatures (stored as XML, so you can create your own signatures if you want) and exports results as an HTML page. Figure A-5. Using Google automatically through SiteDigger A.2.5. SSLDiggerSSLDigger is another free utility from Foundstone (http://www.foundstone.com/resources/proddesc/ssldigger.htm). It performs automatic analysis of SSL-enabled web servers, testing them for a number of ciphers. Properly configured servers should not support weak ciphers. Figure A-6 shows results from analysis of the Amazon web site. Amazon only got a B grade because it supports many weaker (40-bit) ciphers. In its case, the B grade is the best it can achieve since it has to support the weaker ciphers for compatibility with older clients (Amazon does not want to turn the customers away). Figure A-6. SSLDigger: automated analysis of SSL-enabled servers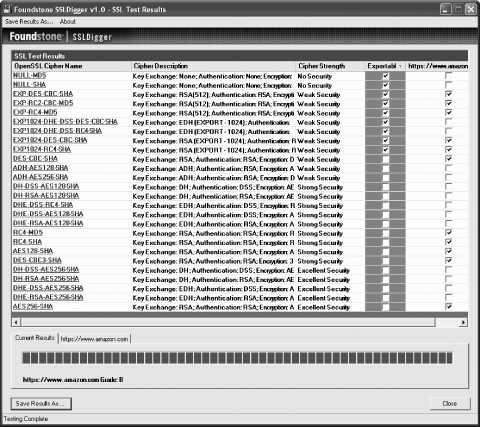 A.2.6. HttprintHttprint (http://net-square.com/httprint/) is a web server fingerprinting tool (not free for commercial use). Unlike other tools, it does not use the forgeable Server header. Instead, it relies on web server characteristics (subtle differences in the implementation of the HTTP protocol) to match the server being analyzed to the servers stored in its database. It calculates the likelihood of the target server being one of the servers it has seen previously. The end result given is the one with the best match. When running Httprint against my own web server, I was impressed that it not only matched the brand, but the minor release version, too. For the theory behind web server fingerprinting, see:
In Figure A-7, you can see how I used Httprint to discover the real identity of the server running www.modsecurity.org. (I already knew this, of course, but it proves Httprint works well.) As you can see, under "Banner Reported," it tells what the Server header reports (in this case, the fake identity I gave it: Microsoft IIS) while the "Banner Deduced" correctly specifies Apache/1.3.27, with an 84.34% confidence rating. Figure A-7. Httprint reveals real web server identities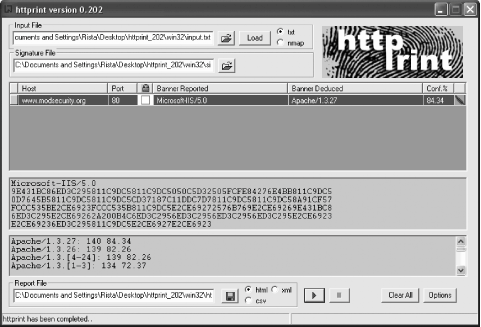 |