| [ Team LiB ] |
|
Session Beans and WebLogic Server ClusteringMany business applications are very sensitive to system failures. Companies have to offer 24/7 availability to remain competitive. To minimize system failures, WebLogic enables you to cluster services across multiple server instances. If one server fails, another server can service the request. Thus, clients will seldom realize that there has been a (partial) system failure, and can continue processing transparently. Cluster provides two advantages to an enterprise:
You can learn more about WebLogic Server clustering in Chapter 36, "Working with WebLogic Server Clusters." In this section, we look at some clustering strategies that can be adopted with relevance to Session EJBs. We look first at clustering Stateless Session EJBs, followed by an examination of Stateful beans. Clustering a Stateless Session BeanAs you already know, EJBs use RMI to communicate between the client and the server. The RMI implementation of the home or remote interface on the client side is known as a stub. A stub is a network protocolaware object that communicates with the server to process client requests. When there's more than one instance of the WebLogic Server within the deployment, the stubs that are created are aware of the physical location of the different servers. In other words, these stubs are "replica-aware." They're intelligent enough to reach out to a second server if the first server fails. Stateless session clustering properties are affected by the <stateless-clustering> stanza (under <weblogic-ejb-jar> In some cases, you might not want some Stateless Beans to be cluster-aware. You have a choice of making the Stateless Bean methods nonclusterable. The optional parameter <stateless-bean-is-clusterable> indicates whether the bean is clusterable. By default, this property is set to True. If the bean is clusterable, calls to the stub will be load-balanced across all the cluster participants where the bean has been deployed. The stub also attempts to failover method calls when any server that it's trying to reach is unreachable due to a possible system failure. Needless to say, you can control the load-balancing behavior of the method calls. Load Balancing StrategyWhen we talk of load balancing requests across different server instances, one logical question is in regard to the algorithm used to perform the load-balancing operation. WebLogic Server enables you to configure a load-balancing algorithm for choosing the server to communicate with. This can be done by configuring the optional <stateless-bean-load-algorithm> tag (under <weblogic-ejb-jar> WebLogic Server also enables you to write your own load-balancing algorithm by specifying your own class name in the property <stateless-bean-call-router-class-name> (under <weblogic-ejb-jar> For example, suppose that XYZ Airlines wants to implement clustering in its enterprise. The airline wants all write methods (such as reserveSeats) to be routed to a set of dedicated write servers, while sending the searches to a set of dedicated read servers. All other functions can be routed using the default load-balancing algorithm of the server. The following is a sample code of a call-router class:
public class AirlineCallRouter implements CallRouter {
private static final String[] writeServers = { "server1", "server3" };
private static final String[] readServers = { "server2", "server4" };
public String[] getServerList(Method theMethod, Object[] params) {
if (m.getName().equals("reserveSeats")) {
return writeServers;
}
if (m.getName().equals("searchFlights")) {
return readServers;
}
return null;
}
}
For more information about clustering, see Chapter 36. Failover StrategyConsider two of the methods that we coded as part of the AirlineReservation EJB: getFlightNumbers (which searches for flights based on the origin and destination cities) and reserveSeats (which actually performs the reservation). Now assume that the stub attempts to perform one of these methods on Server-1. It waits for a while, but eventually receives an error, that isn't a business error (that is, a RemoteException). At this point, assume that the stub retries the request on Server-2, and that the request goes through successfully. This gives us two scenarios, depending on the stage at which the call to Server-1 failed:
In the first case, there's no problem at all. The stub retries the request, receives a successful response, and reports back to the client. However, consider the second case. For the getFlightNumbers method, there is again no problem. That's because although the transaction made it all the way to the end, no data was ever changed, and it doesn't hurt to retry the request and get back the same results. It will definitely impact response time, but it doesn't hurt the integrity of the data. However, with the reserveSeats method, the reservation went through successfully the first time. Therefore, when the request is retried, the seats will be booked twice! This is obviously a serious condition that should be avoided. WebLogic Server achieves this by making the stub retry requests only for idempotent methods. The Free On-line dictionary of computing defines an idempotent function as A function f: D -> D is idempotent if f (f (x)) = f (x) for all x in D. I.e. repeated applications have the same effect as one. Based on this definition of an idempotent function, it's quite obvious that getFlightNumbers is idempotent, whereas reserveSeats is not. WebLogic uses the <stateless-bean-methods-are-idempotent> parameter in the weblogic-ejb-jar.xml deployment descriptor (under <weblogic-ejb-jar> In our case, this isn't sufficient because we have one method that's idempotent and one that isn't. To maximize the failover features of our application, we must identify idempotency on a business-method level, rather than in a global level. To do this, we can use the <idempotent-methods> stanza under the <weblogic-ejb-jar> Clustering a Stateful Session BeanStateful Session Beans also use replica-aware stubs for supporting clustering within a WebLogic Server clustered deployment. The clustering properties of a Stateful Session Bean are controlled by the stanza <stateful-session-clustering> (under <weblogic-ejb-jar> Load Balancing Strategy for Stateful BeansWith Stateless Session Beans, the home interface is considered to be clusterable all the time. The container load balances calls to the home interface. However, with Stateful Session Beans, you have the capacity to override this default behavior. This can be done by setting the parameter <home-is-clusterable> (under <weblogic-ejb-jar> At the same time, the remote object's methods are not load-balanced for Stateful Session Beans because only one bean instance is active at a time per client. Failover Strategy for Stateful BeansBy default, calls to the Stateful Session Bean remote interfaces do not fail over. If a stub receives an exception, it doesn't retry the request. But you can override this behavior by setting the property <replication-type> (under <weblogic-ejb-jar> Just like Stateless Session Beans, Stateful beans can also declare idempotent methods by using the <idempotent-methods> stanza (under <weblogic-ejb-jar> When a server receives a request to create a Stateful Session Bean instance, it creates the instance and identifies a secondary server that will provide failover mechanism for this bean instance. Secondary servers are selected using certain rules as described in Table 21.2. While creating a WebLogic cluster, you can create machine names using the console and associate WebLogic Server instances to each machine. Different servers that are running on the same physical machine will be associated to the same machine using the console. Servers that aren't associated with any machine names are considered by WebLogic Server to be running in different physical machines. A replication group is a logical grouping of servers that determines which server will be chosen as the secondary server for replicating Stateful Session Beans. While defining servers, you can specify replication Groups for each server. You can also specify the name of the preferred replication group for each server. When the server to which the request originally arrives attempts to choose a backup secondary server, it ranks the different servers within the WebLogic Server cluster based on two parameters. The ranking table is shown in Table 21.2.
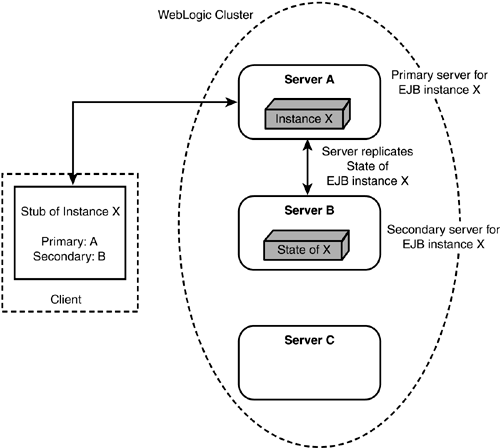
The primary server picks as the secondary server the server that has the lowest rank according to this table. The stub that's created is loaded with the information about the primary and the secondary servers and sent to the client. The entire bean instance isn't replicated across to the secondary server. To conserve resources, only the state information is replicated. All requests from the client continue to go to the primary server (remember, no load-balancing for Stateful Beans). As and when the client makes any changes to the conversational state, the state changes are replicated to the secondary server. For transactional calls, state changes are replicated only after the transaction has committed. For nontransactional calls, state changes are replicated after every call. Figure 21.3 illustrates this process. Figure 21.3. Stateful session clustering.
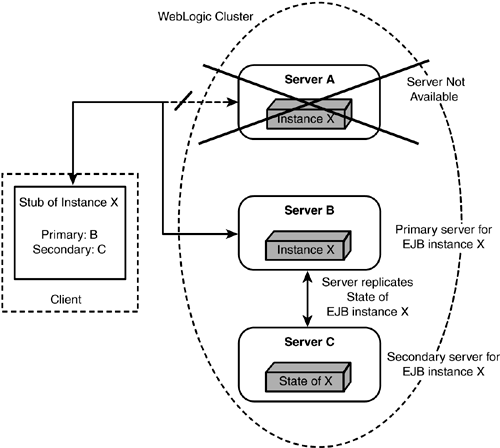
If and when the primary server fails, the stub already has the information needed to contact the secondary server with its request. At this time, the secondary server, which now becomes the primary server, has enough information to re-create the bean instance and the state associated with the client. This server then picks a new secondary server from the available servers list and replicates the state information to the new secondary server. The stub is also updated to reflect the new set of primary and secondary servers on the next method call. This process is illustrated in Figure 21.4. Figure 21.4. Failover scenario for stateful session clustering.
This way, Stateful Session Beans provide a failover mechanism in a clustered environment. Note, however, that this mechanism has a slight chance of a problem. Imagine that the business method has completed successfully, so the primary server attempts to replicate the state of the bean. If the primary server fails at this stage, before it can successfully complete the replication process, the latest state information never gets to the secondary server. The next request will have to deal with the state as it existed prior to the last call made. |
| [ Team LiB ] |
|
 <weblogic-enterprise-bean>
<weblogic-enterprise-bean>