| [ Team LiB ] |
|
Other Useful XML FeaturesWebLogic Server provides several features that you can use for developing XML-based applications. We already looked at one of the key features provided by WebLogic Server: the Streaming API. Apart from that, there are also some other features that can be quite useful. In this section, we briefly look at some of those features. WebLogic Fast ParserIn addition to the Apache Xerces parser that's packaged with WebLogic Server, another parser implementation is included in the package: the WebLogic Fast Parser. This is a high-performance, SAX-based parser that's intended to be used for small- to medium-sized XML documents. Note that this parser does not support DOM. You can use Fast Parser by using the parser class weblogic.xml.babel.jaxp.SAXParserFactoryImpl. Visit the URL http://edocs.bea.com/wls/docs81/xml/xml_apps.html#1084718 for more information. WebLogic Server XML RegistryWebLogic Server provides a good abstraction for configuring several XML parameters using the administration console. For instance, you can configure the parser that you want your application to use instead of the default WebLogic Server parser by using the XML registry. This mechanism enables you to separate the code from the configuration of the parameters in your application. Each server can have a maximum of one registry associated with it. If no registry is associated with a server, the default values are used. You can perform two types of configurations using the XML registry:
While configuring parsers and transformers, you have the flexibility to decide on the parser or transformer at deployment time, and avoid any hard-coding in your application. You can also define multiple parsers/transformers for different XML types. Understand that the parsers defined in the registry will be used only if your code uses JAXP. If you directly use the underlying parser, the registry entries will not be used. CAUTION To use the WebLogic Server XML registry, your application must use JAXP. You can also configure the registry to resolve the external entities used in XML documents. These entities are referenced using a public or a system ID. You can make the server cache these entities locally to avoid the overhead of network access every time an entity is referenced. The external repository from which the entity is retrieved must support a HTTP protocol (such as a URI). You can also configure the server to expire the local cache at regular intervals so that the latest version of the referenced entity is always available for your application. Your code does not explicitly refer to any of these parameters defined in the registry. When you invoke the parser using JAXP, WebLogic Server automatically looks up the registry and uses the appropriate parser. Similarly, when your XML document references the entity, the server knows to look up the registry for local entity caching rules. Configuring a Parser in the RegistryTo configure a parser in a registry, you must first create a new registry. Open the WebLogic Server console, and navigate to the link mydomain
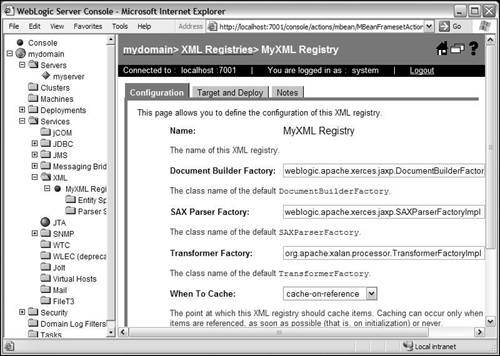
Note that the When to Cache property on this screen provides the default caching mechanism for this XML registry. You can further refine this behavior by explicitly setting appropriate caching strategies for certain entities. Any entity that does not define an explicit caching strategy will use the strategy defined on this screen. The creation process is shown in Figure 29.2. Figure 29.2. Creating a new XML registry.
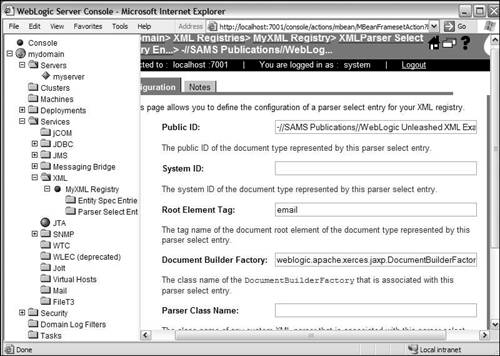
After you've entered all the values, clicking the Create button will create the registry for you. After creating the registry, don't forget to switch to the Target and Deploy tab and select the servers (or clusters) on which you would like your registry to be targeted and deployed. Configuring Parsers for Individual Document TypesAfter you've configured a registry, you can define different parsers for parsing individual document types. Document types are recognized by using the public ID, system ID, or the root element name of the document. CAUTION WebLogic Server searches only the first 1000 bytes of your XML document for known document types. If your DOCTYPE declaration doesn't fall within this limit, the server will use the default parser. To configure parsers for individual documents, you must first create an XML registry. To learn how to create an XML registry, look at the previous section. Remember that this step is optional, and if you don't specify individual settings for each XML type, the default settings from your XML registry are used. When you've created the XML registry, navigate to that entry in the tree view. Exploding this element will show two more elements: Entity Spec Entries and Parser Select Entries. Right-click the Parser Select Entries option and click on the Configure a New XMLParserSelectRegistryEntry option. This will display a form on the right side of the console, where you can specify the public ID, system ID, and root element tag, followed by the document builder factory and SAX parser factory. Make sure that you enter either the public or the system IDs, and the fully qualified root element tag in this form. You will also find another field called Parser Class Name, which you can ignore. That field is provided only for backward compatibility. When you've added all this information, click the Create button to create the registry entry. Configuring individual parsers for different documents is shown in Figure 29.3. Figure 29.3. Configuring the parsers for different documents.
The parser can be retrieved by using a simple JAXP code snippet without knowing anything about which factory is being instantiated. For example, in the following code snippet, we instantiate the factory and get a new parser from it. WebLogic Server automatically hands out an instance of the SAX Parser Factory that we configure in the registry for the particular XML type. import javax.xml.parsers.SAXParserFactory ... SAXParserFactory factory = SAXParserFactory.newInstance(); factory.setValidating(true); SAXParser parser = factory.newSAXParser(); ... Configuring External Entity ReferencesXMLs often refer to external entities. For example, consider the EJB deployment descriptors. The DOCTYPE entry of the file ejb-jar.xml refers to the external entity that provides the DTD for the XML file. This entry is provided in the following code snippet:
<!DOCTYPE web-app PUBLIC
"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
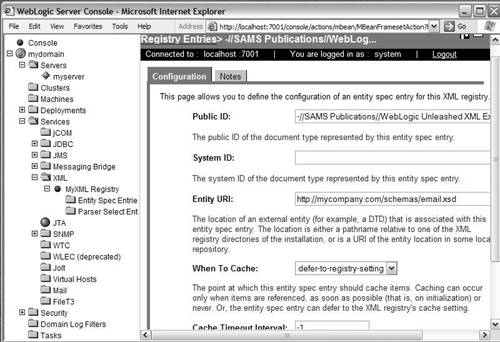
As you can see, we're referring to a DTD that resides on a Sun Microsystems Web site. The parser will obviously have to access this entity to parse the XML and validate it, which it will do over the network. If the parser has to do this network access every time it parses any XML that refers to this entity, it could be quite performance intensive. You can reduce this overhead by configuring the server to cache the entity locally, and refresh the local cache at regular intervals. You can configure the server to cache the entity either at server startup or at the time the entity is first referenced. To configure entity references, you must first create an XML registry. Remember that this step is optional. If you don't perform this step, the server will use the default setting that you specified while creating the registry. After you create an XML registry as described earlier, you can expand the created node on the tree in the WebLogic Server console. This will reveal a node named Entity Spec Entries. Right-clicking this node will reveal an option to create a new entity spec entry. Click on this option. Doing so will populate the right window of the console with a form to create the entry, as shown in Figure 29.4. You can now enter the public ID, system ID, the entity URI from which the entity can be accessed, an option indicating when the server should cache the entity, and a cache timeout interval. Figure 29.4. Configuring the external entities.
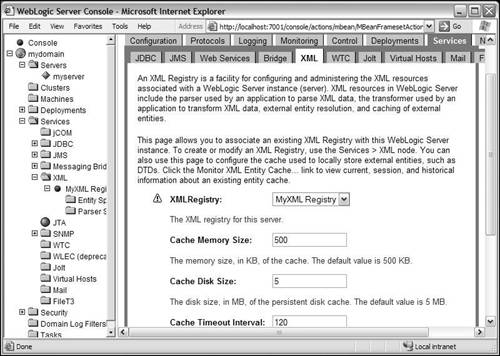
In the choice for server caching strategy, there is an option to defer to registry setting. If you select this, the server will use the default caching strategy chosen when you created the XML registry. By default, the server uses a value of 500KB for the cache memory size, 5MB for the cache disk size, and 120 seconds for the cache timeout interval. You can change these default values of the cache, per server, by clicking on the server under the Servers node in the tree. On the server configuration, click on Services tab, and the XML submenu. There you can configure the server to use the registry that you previously created if you have not deployed the registry already on this server. You can also specify the memory size (in KB) and the disk size (in MB), along with the default cache timeout interval. The process of configuring the cache defaults is shown in Figure 29.5. Figure 29.5. Configuring the server cache.
XPath Pattern MatchingXPath is a W3C standard that allows you to find parts of an XML document, which forms an important part of creating XSLT (XSL-based transformation) rules. It resembles traditional file system paths and identifies various parts of an XML document. For example, look at the following XML shown in Listing 29.6. Listing 29.6 The Book List XML
<booklist>
<book name="Adventures of Tintin Vol. 1">
<publisher>Little Brown & Co </publisher>
<isbn>0316359408</isbn>
<price>14.00</price>
</book>
<book name="The Ultimate Simpsons in a Big Ol' Box">
<publisher>Harperperennial Library</publisher>
<isbn>0060516305</isbn>
<price>35.00</price>
</book>
<book name="Bart Simpson's Guide to Life">
<publisher>Perennial Press</publisher>
<isbn>006096975X</isbn>
<price>15.00</price>
</book>
<book name="Harry Potter and the Order of the Phoenix">
<publisher>Scholastic</publisher>
<isbn>043935806X</isbn>
<price>18.00</price>
</book>
</booklist>
The XPath representation of the root element (booklist) is /booklist while the XPath representation of the publisher element is /booklist/book/publisher Depending upon the context, you may also define relative paths. Relative paths do not begin with the root slash (/), whereas all absolute paths do. XPath expressions can also contain conditions. For instance, to extract all books that are priced at more than $15.00, you would use the following XPath expression: /booklist/book[price > 15] You can also use conditionals on attributes. An attribute is used in a similar way as an element, with the ampersand (@) symbol before its name. For example, to select the book titled Bart Simpson's Guide to Life, use the following XPath expression: /booklist/book[@name = "Bart Simpson's Guide to Life"] XPath also provides useful functions to perform several tasks in your XML. For example, you can get a count of the given tags by using the count() function. For example, count(/booklist/book) returns a count of books in the booklist. We have access to several string manipulation functions (such as concat, contains, and so on) as well as other node set functions (such as last, local-name, and the like). To learn more about XPath, refer to the Web site at http://www.w3schools.com/xpath. WebLogic enables you to use XPath to perform pattern matching within an XML file. An XML document can be represented as a DOM tree, an XMLNode, or an XMLInputStream. You can use the following classes depending on the representation of your XML document, to perform XPath pattern matching. To discuss the various types of XPath classes, we use the email XML file shown in Listing 29.7. Listing 29.7 The Email XML
<email>
<from name="John Doe" id="johndoe@xyzcompany.com"/>
<to name="Jane Doe" id="janedoe@xyzcompany.com"/>
<to name="SomeOther Doe" id="someotherdoe@xyzcompany.com"/>
<cc name="YetAnother Doe" id="yetanotherdoe@xyzcompany.com"/>
<subject z="a" t="b" c="c">Hello!</subject>
<options>
<read_receipt/>
<priority type="Normal"/>
</options>
<body><![CDATA[Hello]]></body>
</email>
If your document is represented as a DOM tree, you can use the DOMXPath class. We'll use this class to count the number of people to which this email is being sent. To do this, we'll first parse the document using a DOM parser and get the Document object. You can read more about this step in earlier sections of this chapter. Following this, we'll create a DOMXPath object, passing to it the XPath query that we want to execute. In this case, we want to query the number of to addresses:
DOMXPath numRecipientsXPath = new DOMXPath("count(email/to)");
The next step is to run this query on the Document object created earlier. You can do this by invoking one of the evaluateAsXXX methods present in this object. Because we're dealing with a count, we expect to receive from the query a number represented as a double in the DOMXPath object. Thus, the following code snippet provides us with the count: double numRecipients = numRecipientsXPath.evaluateAsNumber(theDocument); Depending on your XPath query, the output may be a type of data other than a double. Instead of a double, you can get back a boolean (use evaluateAsBoolean) or a String (use evaluateAsString) from your query. Your query can also return a set of nodes (Set of org.w3c.dom.Node), in which case you'll invoke the evaluateAsNodeset method on the object. This method returns a set (java.util.Set) that contains objects of type org.w3c.dom.Node. The example com.wlsunleashed.xml.xpath.DOMRepresentation illustrates a simple XPath query. Invoke this example using the fully qualified path to the email.xml file, which is also provided. The following code is a function from this sample, which indicates how certain nodes are obtained from the XML and printed out: private void listRecipients() throws XPathException { DOMXPath recipientsXPath = new DOMXPath("email/to"); Set recipients = recipientsXPath.evaluateAsNodeset(document); Iterator iter = recipients.iterator(); System.out.println("This email is being addressed to"); while (iter.hasNext()) { Node aNode = (Node) iter.next(); System.out.println("* " + aNode.getAttributes().getNamedItem("name") .getNodeValue()); } recipientsXPath = new DOMXPath("email/cc"); recipients = recipientsXPath.evaluateAsNodeset(document); iter = recipients.iterator(); System.out.println("This email is being copied to"); while (iter.hasNext()) { Node aNode = (Node) iter.next(); System.out.println("* " + aNode.getAttributes().getNamedItem("name") .getNodeValue()); } StreamXPathThe StreamXPath class is used to perform XPath matches on an XMLInputStream object. Although conceptually similar to DOMXPath, its use is a little different, as you'll see in this section. To use this class, you must first create the object, passing in the query to be performed. In our example, we're simply going to list all the To addresses in the email.xml file. In the following snippet, we instantiate a StreamXPath object, whose root is set at the particular node (to):
StreamXPath recipientsXPath = new StreamXPath("email/to");
The next step is to create a factory of type XPathStreamFactory and register the XPath object as a listener. Remember that because WebLogic XML Streaming is SAX-based, the processing isn't as straightforward as using a DOM tree. To register the XPath object as a listener, you must instantiate an object that implements the XPathStreamObserver interface. In our example, we create an inline class that processes the events received. This interface contains three methods:
Thus, in our example, we use the following code snippet: XPathStreamFactory factory = new XPathStreamFactory(); factory.install(recipientsXPath, new XPathStreamObserver() { public void observe(XMLEvent event) { System.out.println( "Observing Event " + event.getName()); processEvent(event); } public void observeAttribute(StartElement e, Attribute a) { System.out.println( "Observing Attribute " + a.getName() + " on element " + e.getName()); } public void observeNamespace(StartElement e, Attribute a) { System.out.println( "Observing Namespace " + a.getName() + " on element " + e.getName()); } }); As you can see from this code, we simply print out the message received. The processEvent method prints out additional information about each event received. The final step is to actually trigger processing. To do this, we'll first create an XMLInputStream by using an instance of the XMLInputStreamFactory class. For more information about this, read the "WebLogic Server XML Streaming API" section earlier in this chapter. We would normally have processed the stream that we received, but because we need to perform pattern matching, we'll create a new stream by passing this stream into the XPathFactory instance. You can now process the events from this stream. This will also generate events and send them to the XPath object when there are matches based on the query. This is demonstrated in the following code snippet:
XMLInputStreamFactory streamFactory =
XMLInputStreamFactory.newInstance();
XMLInputStream inputStream = streamFactory.newInputStream(
new FileInputStream(fileName));
XMLInputStream searchStream = factory.createStream(inputStream);
while (searchStream.hasNext()) {
XMLEvent anEvent = searchStream.next();
}
As you can see from the while loop, we don't perform any processing with the events generated, but simply parse through the stream. The processing occurs in the StreamXPath object on events that match the given search criteria. The complete source code is provided in com.wlsunleashed.xml.xpath.StreamRepresentation.java. Invoke this file, and pass in the complete path to the Email.xml file, which is also provided. XML EditorBEA offers a tool for editing XML documents. Obviously, you can edit XML documents with any editor such as vi or WordPad. But this editor provides some XML-specific features, such as validation of the XML document, and so on. You can download the XML Editor from the BEA dev2dev Web site by accessing the link http://dev2dev.bea.com/resourcelibrary/utilitiestools/xml.jsp. The XML Editor is a pure Java XML editor, which lets you both create and edit XML files. The editor displays XML files in both a hierarchical tree form as well as a text form. It validates the document using either DTDs or XML Schemas, or simply parses them without validation. The editor supports Unicode. You can use drag-and-drop features using the tree display. The editor provides you with features that will let you insert items into the XML as mentioned in the DTD. The usage of the XML Editor is demonstrated in Figure 29.6. Figure 29.6. Using the BEA XML Editor.
XMLBeansXMLBeans is a new way of parsing and working with XML documents . It enables you to work with Java objects to access the contents of the XML rather than use the traditional parser approach. The Java objects are generated on the basis of the schema that describes the XML document, so it's mandatory that you have a schema that defines your XML document. After they're generated, the objects can be accessed very intuitively. For example, imagine accessing your XML document by making calls such as emailDocument.getToAddressList(). To learn more about XMLBeans, refer to the BEA Web site at http://dev2dev.bea.com/technologies/xmlbeans/overview.jsp. |
| [ Team LiB ] |
|
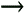 services
services