|
|
XML InstancesThe structure and formatting of XML in an XML document must follow the rules of the XML instance syntax. The term instance Document PrologXML documents contain an optional prolog Typically the prolog serves up to three roles:
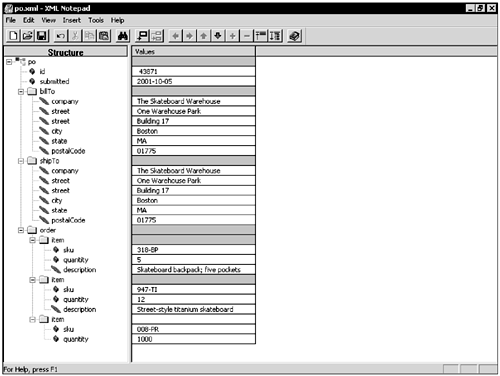
A document can be identified as an XML document through the use of a processing instruction <?PITarget ...?> PIs are enclosed in <? ... ?>. The PI target is a keyword meaningful to the processing application. Everything between the PI target and the ?> marker is considered the contents of the PI. In general, data-oriented XML applications do not use application-specific processing instructions. Instead, they tend to put all information in elements and attributes. However, you should use one standard processing instruction—the XML declaration <?xml version="1.0" encoding="UTF-8"?> The version parameter of the xml PI tells the processing application the version of the XML specification to which the document conforms. Currently, there is only one version: "1.0". The encoding parameter is optional. It identifies the character set of the document. The default value is "UTF-8". Note UTF-8 is a variable-length character encoding standard that generates 7-bit safe output. This type of output makes it easy to move XML on the Internet using standard communication protocols such as HTTP, SMTP, and FTP. Keep in mind that XML is internationalized by design and can support other character encodings such as Unicode and ISO/IEC 10646. However, for simplicity and readability purposes, this book will use UTF-8 encoding for all samples. If you omit the XML declaration, the XML version is assumed to be 1.0, and the processing application will try to guess the encoding of the document based on clues such as the raw byte order of the data stream. This approach has problems, and whenever interoperability is of high importance—such as for Web services—applications should always provide an explicit XML declaration and use UTF-8 encoding. XML document prologs can also include comments that pertain to the whole document. Comments use the following syntax: <!-- Sample comment and more ... --> Comments can span multiple lines but cannot be nested (comments cannot enclose other comments). Everything inside the comment markers will be ignored by the processing application. Some of the XML samples in this book will use comments to provide you with useful context about the examples in question. With what you have learned so far, you can extend the purchase order example from Listing 2.1 to include an XML declaration and a comment about the document (see Listing 2.2). Listing 2.2 XML Declaration and Comment for the Purchase Order<?xml version="1.0" encoding="UTF-8"?> <!-- Created by Bob Dister, approved by Mary Jones --> <po id="43871" submitted="2001-10-05"> <!-- The rest of the purchase order will be the same as before --> ... </po> In this case, po is the root element of the XML document. ElementsThe term element Element names can include all standard programming language identifier characters ([0-9A-Za-z]) as well as underscore (_), hyphen (-), and colon (:), but they must start with a letter. customer-name is a valid XML element name. However, because XML is case-sensitive, customer-name is not the same element as Customer-Name. According to the XML Specification, elements can have three different content types. They can have element-only content, mixed content, or empty content. Element-only content consists entirely of nested elements. Any whitespace separating elements is not considered significant in this case. Mixed content refers to any combination of nested elements and text. All elements in the purchase order example, with the exception of description, have element content. Most elements in the skateboard user guide example earlier in the chapter had mixed content. Note that the XML Specification does not define a text-only content model. Outside the letter of the specification, an element that contains only text is often referred to as having data content; but, technically speaking, it has mixed content. This awkwardness comes as a result of XML's roots in SGML and document-oriented applications. However, in most data-oriented applications, you will never see elements whose contents are both nested elements and text. It will typically be one or the other, because limiting the content to be either elements or text makes processing XML much easier. The syntax for elements with empty content is a start tag immediately followed by an end tag, as in <emptyElement></emptyElement>. Because this is simply too much text, the XML Specification also allows the shorthand form <emptyElement/>. For example, because the last item in our purchase order does not have a nested description element, it has empty content. Therefore, we could have written it as follows: <item sku="008-PR" quantity="1000"/> XML elements must be strictly nested. They cannot overlap, as shown here: <!-- This is correct nesting --> <P><B><I>Bold, italicized text in a paragraph</I></B></P> <!--Bad syntax: overlapping I and B tags --> <P><I><B>Bold, italicized text in a paragraph</I></B></P> <!-- Bad syntax: overlapping P and B tags --> <B><P><I>Bold, italicized text in a paragraph</I></B></P> The notion of an XML document root implies that there can be only one element at the very top level of a document. For example, the following would not be a valid XML document: <first>I am the first element</first> <second>I am the second element</second> It is easy to think of nested XML elements as a hierarchy. For example, Figure 2.1 shows a hierarchical tree representation of the XML elements in the purchase order example together with the data (text) associated with them. Figure 2.1. Tree representation of XML elements in a purchase order.
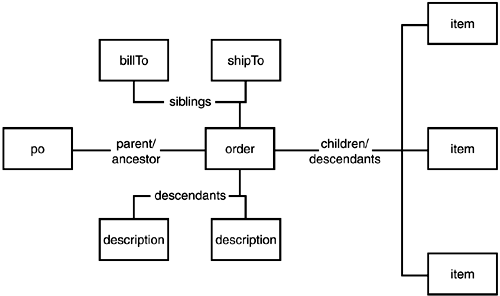
Unfortunately, it is often difficult to identify XML elements precisely in the hierarchy. To aid this task, the XML community has taken to using genealogy terms such as parent, child, sibling, ancestor, and descendant. Figure 2.2 illustrates the terminology as it applies to the order element of the purchase order:
Figure 2.2. Common terminology for XML element relationships.
AttributesThe start tags for XML elements can have zero or more attributes. An attribute is a name-value pair. The syntax for an attribute is a name (which uses the same character set as an XML element name) followed by an equal sign (=), followed by a quoted value. The XML Specification requires the quoting of values; both single and double quotes can be used, provided they are correctly matched. For example, the po element of our purchase order has two attributes, id and submitted: <po id="43871" submitted="2001-10-05"> ... </po> A family of attributes whose names begin with xml: is reserved for use by the XML Specification. Probably the best example is xml:lang, which is used to identify the language of the text that is the content of the element with that attribute. For example, we could have written the description elements in our purchase order example to identify the description text as English: <description xml:lang="en">Skateboard backpack; five pockets</description> Note that applications processing XML are not required to recognize, process, and act based on the values of these attributes. The key reason why the XML Specification identified these attributes is that they address common use-cases; standardizing them would aid interoperability between applications. Without any meta-information about an XML document, attribute values are considered to be pieces of text. In the previous example, the id might look like a number and the submission date might look like a date, but to an XML processor they will both be just strings. This obviously causes some headaches when processing data-oriented XML, and it is one of the primary reasons most data-oriented XML documents have associated meta-information described in XML Schema (introduced later in this chapter). At the same time, XML applications are free to attach any semantics they choose to XML markup. A common use-case is leveraging attributes to create a basic linking mechanism within an XML document. The typical scenario involves a document having duplicate information in multiple locations. The goal is to eliminate information duplication. The process has three steps:
The purchase order example offers the opportunity to try this out (see Listing 2.3). As shown in the example, in most cases, the bill-to and ship-to addresses will be the same. Listing 2.3 Duplicate Address Information in a Purchase Order
<po id="43871" submitted="2001-10-05">
<billTo>
<company>The Skateboard Warehouse</company>
<street>One Warehouse Park</street>
<street>Building 17</street>
<city>Boston</city>
<state>MA</state>
<postalCode>01775</postalCode>
</billTo>
<shipTo>
<company>The Skateboard Warehouse</company>
<street>One Warehouse Park</street>
<street>Building 17</street>
<city>Boston</city>
<state>MA</state>
<postalCode>01775</postalCode>
</shipTo>
...
</po>
There is no reason to duplicate this information. Instead, we can use the markup shown in Listing 2.4. Listing 2.4 Using ID/IDREF Attributes to Eliminate Redundancy
<po id="43871" submitted="2001-10-05">
<billTo id="addr-1">
<company>The Skateboard Warehouse</company>
<street>One Warehouse Park</street>
<street>Building 17</street>
<city>Boston</city>
<state>MA</state>
<postalCode>01775</postalCode>
</billTo>
<shipTo href="addr-1"/>
...
</po>
We followed the three steps described previously:
The attribute names id and href are not required but nevertheless are commonly used by convention. You might have noticed that now both the po and billTo elements have an attribute called id. This is fine, because attributes are always associated with an element.
Character DataAttribute values as well as the text and whitespace between tags must follow precisely a small but strict set of rules. Most XML developers tend to think of these as mapping to the string data type in their programming language of choice. Unfortunately, things are not that simple. EncodingFirst, and most important, all character data in an XML document must comply with the document's encoding. Any characters outside the range of characters that can be included in the document must be escaped and identified as character references Unfortunately, for obscure document-oriented reasons, there is no way to include character codes 0 through 7, 9, 11, 12, or 14 through 31 (typically known as non-whitespace control characters WhitespaceAnother legacy from the document-centric world that XML came from is the rules for whitespace handling. It is not important to completely define these rules here, but a couple of them are worth mentioning:
Luckily, most data-oriented XML applications care little about whitespace. EntitiesIn addition to character references, XML documents can define entities
For example, to include a chunk of XML as text, not markup, inside an XML document, all special characters should be escaped:
<example-to-show>
<?xml version="1.0"?>
<rootElement>
<childElement id="1">
The man said: "Hello, there!".
</childElement>
</rootElement>
</example-to-show>
The result is not only reduced readability but also a significant increase in the size of the document, because single characters are mapped to character escape sequences whose length is at least four characters. To address this problem, the XML Specification has a special multi-character escape construct. The name of the construct, CDATA section <example-to-show><![CDATA[ <?xml version="1.0"?> <rootElement> <childElement id="1"> The man said: "Hello, there!". </childElement> </rootElement> ]]></example-to-show> A Simpler Purchase OrderBased on the information in this section, we can re-write the purchase order document as shown in Listing 2.4. Listing 2.4 Improved Purchase Order Document<?xml version="1.0" encoding="UTF-8"?> <!-- Created by Bob Dister, approved by Mary Jones --> <po id="43871" submitted="2001-10-05"> <billTo id="addr-1"> <company>The Skateboard Warehouse</company> <street>One Warehouse Park</street> <street>Building 17</street> <city>Boston</city> <state>MA</state> <postalCode>01775</postalCode> </billTo> <shipTo href="addr-1"/> <order> <item sku="318-BP" quantity="5"> <description>Skateboard backpack; five pockets</description> </item> <item sku="947-TI" quantity="12"> <description>Street-style titanium skateboard.</description> </item> <item sku="008-PR" quantity="1000"/> </order> </po> |
|
|