|
|
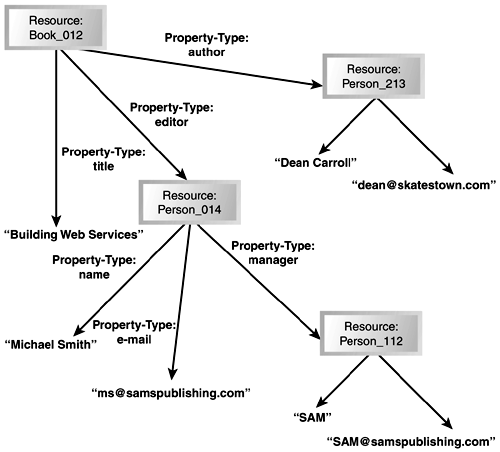
Ontologies and the Semantic WebToday's Web was originally designed for use by humans. It is now slowly being extended for use by machines. It can be argued, however, that all the current work in standards, protocols, interoperability stacks, and so on, are just facilitating the placement of bits on the wire, with little effort going to actually facilitate understanding the meaning of those bits and the content of the data being transmitted. If the eventual goal of the evolution of the Web is to facilitate integration between human tasks and machine tasks, meaning and context must be taken into account. At a minimum, it is clear that fundamental tasks, such as searching and task interoperability in general, would be greatly enhanced if the machines being used for the tasks had some semantic knowledge of the data. Resource Description FrameworkOf course, there have been numerous discussions as to what constitutes understanding. Leaving such discussions for the academic types, let us at least agree to require that Web content, and resources in general, be marked up with some structured metadata that can be processed by machines. Metadata is an essential component that facilitates tasks in everyday life and would be similarly beneficial if introduced into the framework of Web services. XML is the first installment that makes structured metadata possible, but XML is just a language, and another layer of meaning has to be built on top of it. This layer of meaning is increasingly being exposed through the Resource Description Framework (RDF) RDF, as the name implies, is a framework that enables you to describe resources as structured metadata, and to exchange and reuse these resources in various possibly unrelated applications. It is built on the three concepts (see Figure 9.4):
Figure 9.4. An example resource definition for a Web services book authored by Dean Carroll and published by Sams.
A simple RDF example that defines a small subset of the graph shown in the Figure 9.4 follows:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:books="urn:X-Skatestown.com/rdf/books/">
xmlns:who="urn:X-Skatestown.com/rdf/who/">
<rdf:Description rdf:ID="Book_012"
rdf:about="http://skatestown.com/books/webservices">
<books:title>Building Web Services</books:title>
<books:author rdf:HREF="#Person_213"</books:author>
<books:editor rdf:HREF="#Person_014"</books:editor>
</rdf:Description>
<rdf:Description rdf:ID="Person_213"
rdf:about="http://skatestown.com/people/dean">
<who:name>Dean Carroll</who:name>
<who:email>dean@skatestown.com</who:email>
</rdf:Description>
</rdf:RDF>
OntologiesHaving a framework to define resources and their relationship is only the first step. What if different applications use different identifiers from different RDF definitions to mean the same thing? In order for them to interoperate and exchange information, they must reconcile the two terms. This next layer of meaning on top of RDF is provided by ontologies. The term ontology, originally meaning "concerned with the nature and relations of being" (Merriam-Webster), has been abused by different communities. In general AI circles, it has come to mean a document containing a set of formal definitions of relations among terms. Common ontologies contain a taxonomy of terms and a set of inference rules to make sense of the terms, usually in machine readable form. This will allow a computer, for example, to know that the terms author and creator, found in two different schemas, actually mean the same thing when applied to a book. Currently, the most comprehensive and widely accepted effort that extends XML and RDF for specifying and manipulating ontologies is DAML+OIL, a joint effort combining a DARPA sponsored language, DARPA Agent Markup Language (DAML), and a European Union Information Society Technologies sponsored language, Ontology Inference Layer or Ontology Interchange Language (OIL). DAML+OIL defines core resources and a large number of ontologies. For more information, see the "Resources" section at the end of this chapter. Relating RDF to Web ServicesSemantic Web technologies are clearly tightly related to Web services technologies and will eventually converge. For example, Web services providers can currently describe their services through WSDL and then register them on a UDDI registry, categorizing them according to some taxonomy in order to be discovered. Whereas current service descriptions and UDDI taxonomies are intended for human readers to browse, Web service descriptions and registries that are marked up using RDF and ontologies as a semantic enhancement to WSDL and UDDI can be machine readable, enabling dynamic discovery and invocation of services by software through common terminology and shared meaning. Several projects are underway to semantically enhance Web services by exploring the concept of marked up Web services. For example, the latest effort from DAML is DAML-S, a DAML-based Web service ontology to allow marking up Web services for automated discovery and invocation by software agents. Again, more references are provided in the "Resources" section. |
|
|