9.8. Scaling Large DatabaseSome very large information clusters can't be easily federated. If we have a very large users table, we don't necessarily want to split it up into chunks as we'd then have to search through every shard whenever someone logged inwe'd need to find the user's record and we wouldn't know the shard number, only the username. For clusters of data like this that need to scale up, we want some kind of multimachine setup with good redundancy where we can failover hot when machines die. We can't easily do this with a replication setup, as the master is a single point failure. Instead, we want to get data onto all machines in the cluster simultaneously so that we can afford to lose any server at any time without losing any data. For synchronous writes across a cluster, we can either use a synchronous replication mode or write to all machines at once ourselves. Oracle offers some synchronous replication modes, but using Oracle for a portion of our infrastructure gives us yet another esoteric technology to support. MySQL's NDB gives us synchronous replication, but isn't ready for large usage yet. Doing it ourselves is currently the order of the day, so how can we approach it? We could write to all machines in the cluster each time we need to make a write. This would mean our write speed is bound by the slowest node in the cluster, but that's probably acceptable. The real problem then occurs when a machine dieswrites stop for the downed machine, but there's no path for recovery. We can't stop another machine and clone from it as we can with replication because those two machines would miss all the writes performed while we were cloning. What we need is something like the replication loga journal of write actions that we can replay on machines that go down. To build this journal, we really need to get all writes into a single place; time to add another layer, shown in Figure 9-17. Figure 9-17. Adding a write-through cache layer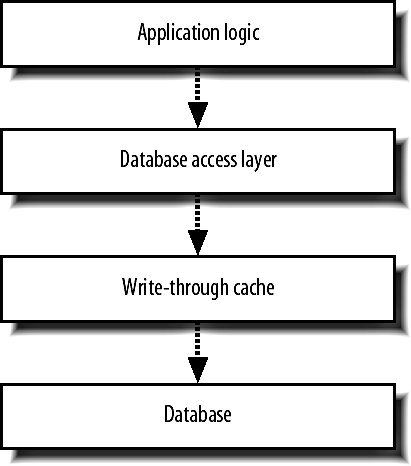 By creating a write-through layer, we can abstract the work involved with keeping multiple machines up-to-date out of the application code. The write-through layer receives SQL commands and passes them onto all of the nodes, keeping track of which nodes are active and which are down. When we have down nodes, we write a journal for them to replay once they're back. We need to make sure that multiple machines in the write-through layer record this journal to avoid the layer being our single point of failure. When nodes are up, we can perform a synchronous write across all machines. A node in the cluster will always be in one of three states: synchronous, disabled, or catching up. We only want to read from synchronous machines to get a fresh copy of data, but the only component in our system that knows the status of each node is the write-through layer itself. If we also build read handling into our write-through layer, we can balance reads only between synchronous machines to guarantee fresh reads. In this case, our write-through layer can become an effective place to house a write-through cache. We can cache read data in memory in the layer and always invalidate it perfectly because all writes to the data go through the layer. This means the write-through cache needs to understand elements of the schema to figure out what it can cache, rather than the completely generalized architecture of simply replicating writes and balancing reads. Whether you'll need this level of sophistication is not always clear, especially when you have other caching methods that are working well. |