9.9. Scaling StorageAs your database grows larger, the files that comprise the table space will grow too, often into hundreds of gigabytes. A few files at a hundred gigabytes is no big deal for disks these dayswe can buy cheap 500 GB disks for spacewhile the file count from most databases is trivial, although even for databases we have a bit of a problem to watch out for. As we increase the rate of reads and writes on our disks, the higher the chance that they will fail, which is annoying, since they were already the component most likely to fail. What we need is some redundancy. We might already have redundancy outside of the machine by having several clones available, but having clones is expensive. If we can make each node more reliable for less money than running clones (and administering the failover process) then we can keep fewer clones by reducing the chance of any single node dying. To be able to scale out a storage platform, we need to ensure we can handle the number and volume of files we need, while keeping everything nicely redundant. 9.9.1. FilesystemsModern filesystems can support hundreds of thousand of files in a single directory with no ill effects. Unfortunately, the filesystems we typically use under Unix are not particularly modern. When finding a file on a filesystem within a directory, we need to check the file table to find its inode. Imagine our application requested the file /frobs/92363212.dat from the disk. We first lookup the frobs folder in the root of the namespace. We walk the list of root objects and find the folder. We then open the index for the folder and walk the list until we find an entry for 92363212.dat with the inode we need. The problem arises when we have a lot of files in the folder. With 100,000 files in the folder, we need to walk a list of 100,000 names, performing a string match against each to see if it's the file we're looking for. As we add more files, the problem gets worse. To support many files per folder, we need to use a filesystem that does nonsequential walks of the directory index to find the file entry. Both Reiser and ext3 on a 2.6 kernel achieve this by using a hash of the filename to lookup the inode entry, massively speeding up lookups. As the number of files in the directory increases, the time spent looking up an entry for each file remains relatively constant. When we're working with a lot of files on a single set of disks, there are some filesystem options that should interest us. The Reiser journal can be tuned for speed of writing against speed of recovery. For a reduced journaling overhead, we take a hit recovering the disk after a large failure, while we can ensure quick recovery at the price of write performance. To achieve better read and write performance, it's nearly always a good idea to add the noatime flag when mounting a filesystem. atime is short for access time. By default, Unix will store the time a file was last accessed (for read or write), but this means that we need to perform a small write for each read. Writes are typically more expensive than reads, so adding a write to every read can really kill performance. The noatime flag avoids recording atime stamps against each fileunless you specifically need atime values for your application, adding the flag will give you a big boost in read and write capacity. 9.9.2. ProtocolsFor any storage component, we need to decide how we're going to read and write files from and to the storage. For locally attached disks this is easywe just read and write to the filesystem as usual. The problem comes when we have storage shared between multiple machines. To write to unattached storage, we need some kind of interface and protocol for talking to the machine hosting the storage (often referred to as the head). The easiest way to talk to remote disks under Unix is by mounting them using the network filesystem, NFS. NFS allows you to mount remote disks to appear as local volumes, allowing you to read and write to them as you would any local volume. NFS has historically had some issues with both performance and failover semantics. In previous versions of NFS, a crashed server would cause significant problems on clients under Linux. For "soft" mounts, writes to a crashed server would be thrown away silently while "hard" mounts would put the writing process into "D" state. "D" state, which means uninterruptible sleep, is a magical status for processes that renders them completely untouchable. A process in "D" state can't be killed and is fixed only by rebooting the machine. The dead remote server can then not be unmounted or even remounted when it comes back online. The client machine (or machines) will need to be rebooted. Using the NFS intr (interruptible) mode allows the client to recover when the server comes back online, but the client will hang until that point. Different versions of NFS react in different ways to server outages, so it's very important that you test such scenarios before using NFS in production. If nothing else, having a recovery plan for when NFS does lock up is a good idea. NFS is designed to allow you access to remote filesystems in such a way that they appear local. This is great for many applications, but is overkill for the file warehousing often associated with web applications. The typical requirements we have for file storage are to write a file, read a file, and delete a file, but never operations within a file, modifications, and appendages. Because NFS offers more than we need, it incurs extra overhead we wouldn't have in a dedicated protocol. NFS also keeps open a socket for every volume mounted between every client and server, adding significant network overhead even when no work is taking place. To get around the limitations of NFS, we can use different protocols that more closely match our needs. To cover simply putting and deleting files, we can use FTP (or SCP for the security conscious), which cuts out any of the persistence overhead. For reading, we can use HTTP from our storage servers. For serving files to other machines within our application, we can use a kernel HTTPD such as TUX (http://www.redhat.com/docs/manuals/tux/) for ultra-lightweight serving. This conveniently allows us to load balance file reads using our standard HTTP load-balancing system. We can also use HTTP for our writes, using the PUT and DELETE methods. By using a copy of Apache and some custom code we can then do all of our storage I/O over HTTP. When using HTTP, we don't get the benefit of reading and writing to filesystems as if they we mounted locally, but most programming environments are going to allow us to easily work with files over HTTP, reducing the amount of work involved with integrating the storage with the application. The other alternative is to create some custom protocol and software. This might be sensible if you need to add some custom semantics not available in other protocols, or you need a massive level of performance. For a federated filesystem (which we'll talk about later in this chapter), the storage protocol may need to return extra status about the final location of a file during storage, the synchronicity of deletes, and so forth. A custom protocol would allow us to do this, but it's also worth remembering that HTTP is a fairly extensible protocolwe can add request and response headers to convey any special application-specific semantics, giving us the flexibility of a custom system with the interoperability of HTTP. 9.9.3. RAIDIf we want redundancy, we need multiple copies of our data. If we want capacity we need to be able to array disks together to make larger disks. This is where Redundant Arrays of Independent Disks (or RAID) come in, allowing us to mirror data for redundancy while creating volumes larger than a single disk for scale. RAID encompasses a wide range of configurations, allowing us to create systems designed for scale, redundancy, or any mix of the two. The different RAID configurations are known as modes , and each mode is given a distinct number. When modes are combined, their names are concatenated, so RAID 1 with RAID 5 is known as RAID 1+5 or RAID 15. There are five core RAID modes (including the popular combinations) that are commonly used, as shown in Table 9-1.
Striping and mirroring are at the core of the RAID mentality. Striping data means that for each data unit (byte, block, etc.) we put parts of the data on different disks. This means that, while reading or writing the data unit, we read or write from several disks in parallel to get higher performance. Both reading and writing have a small overhead in splitting and assembling the pieces, but the combined I/O throughput (twice as much for two disks, three times as much for three disks, etc.) makes overall reads and writes faster. In a mirroring setup, the contents of one disk are mirrored on another, giving us redundancy in the case of a failed disk. Mirrored setups sometimes take a slight write performance hit for checking that both copies have been written and a slight read hit for checking that checksums match between the two mirrored volumes. This is not very common in practice, as the disk's onboard error detection and correction handle that. In an ideal setup, both disks would be read from, simultaneously giving us double read capacity, but most RAID controllers will read from only one disk. To add a level of redundancy without having to double the disks for mirroring, some striped systems have parity stripes. The idea behind parity data is fairly simpleif we have four disks in a set with one parity disk, a quarter of the data gets written as a single stripe to each of the four disks and an extra parity stripe gets written to the parity disk. The parity stripe is a special sum of the other four stripes in such a way that when any one of the other stripes is lost, it can be rebuilt based on the other stripes and the parity stripe. By keeping a parity stripe, we can recover the loss of any single stripe (including the parity stripe itself). Parity modes cause a fair amount of write overhead, as the parity for data must be calculated first. Through the combination of RAID modes, there are literally an infinite amount of possible configurations (mirror of stripes, mirrors of parity striped sets, etc.), although there are some other core modes that are less popular than the big five, as shown in Table 9-2.
With a dual parity configuration, as in RAID 4, we keep two parity blocks for every data block, allowing us to lose up to two disks without losing data. We can add further parity blocks, but each one we keep increases read and write overhead and at some point, it makes more sense to mirror the data. NetApp Filers use a variation on RAID 4 to allow two disks to fail in a set without data loss, still avoiding the disk overhead of RAID 10. RAID can be emulated in software, but is typically the realm of a hardware RAID controller. The hardware controller deals with the creation and maintenance of the RAID set, presenting the set to the OS as a single device on which we can create volumes. The RAID set then acts exactly as a single attached diskour application can treat it as such. The difference is that when a disk fails, as they are prone to do, we can carry on as if nothing had happened. In the case of a failure, the RAID controller handles the failover to the working disks and the subsequent rebuilding of the set once the disks are replaced. Mirrored and parity sets have the ability to repopulate a new disk once it's been swapped for a dead one, although read and write performance still suffer during the process. Depending on the controller, tools will be needed to monitor disk failure and administer the adding and removing of drives. This monitoring should form part of your core monitoring setup that we'll talk about in Chapter 10. For storage shared between multiple hosts, we can hook up a RAID set to a simple head machine via SCSI or SATA and serve files over NFS or HTTP, but sometimes our needs will outgrow the disks that can be housed in a single machine. Outside of a machine casing but within the same rack, we can add what's called direct attached storage, where a shelf of disks is connected to a head machine via a connection like SCSI or SATA. This is fine up to a certain size and throughput, but lacks some other capabilities, such as hot failover of head machines and I/O buses. For standalone storage clusters we have the option of having either a network attached storage (NAS) or storage area network (SAN). The difference between the two is usually that a SAN uses a dedicated network for transferring data (referred to as the storage switch fabric) and that a SAN moves data using a block-level protocol rather than a file-level protocol. While you might request a file over NFS from a NAS cluster, you would request a block of data using SCSI from a SAN. Modern SANs can also use iSCSI (SCSI over TCP/IP) so that connections can be made with regular Ethernet rather than a fiber fabric. For large and powerful storage clusters, if often makes sense to look at the large storage appliance vendors. NetApp "filers" are a self-contained storage cluster with up to 100 TB of disk, multihead and multibus redundancy, replication software, and all the good stuff you might want. Of course, this all comes at a price, but as your storage capacity grows it becomes more and more cost-effective. Using small 1 TB boxes for storage is a lot cheaper initially, but as time goes by the administration of machines makes a real impact on TCO. The administration of a single filer versus one hundred Linux boxes makes large appliances an attractive choice. There are several big vendors for large-scale storage and it's worth looking into their various strengths before deciding either way. Rackable's OmniStor series, SGI's InfiniteStorage range, and Sun's StorEdge are just three possible options. 9.9.4. FederationIf a large NetApp filer can give you 100 TB of storage space (that's one hundred billion bytes), what will you do when you need more? This question is at the core of scalingwhat will you do when you outgrow the maximum capacity of your current configuration? As with every component of a large system, the key to both scaling and redundancy is to have components we can grow by simply duplicating hardware. To achieve this with our storage layer, we need to build our system in such as way as to allow federation of file storage. As with database federation, we have multiple shards that each contain a portion of the entire dataset. Because storage has a hard limit, unlike database query performance, we tend to want to structure the system slightly differently to database federation. Instead of keeping all of the files for a single user on a single shard, we can scatter the files across multiple shards. As shown in Figure 9-18, the key to retrieving those files is then to interrogate the database: we need to store the location of each file (its shard number) next to a record relating to that file. Figure 9-18. Scattering files across multiple shards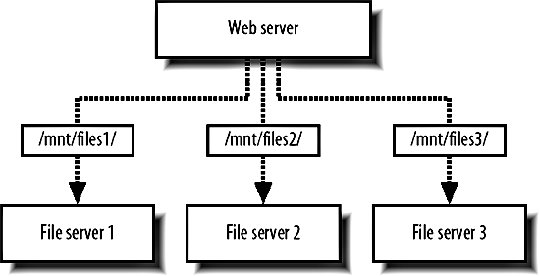 In order to grow our storage capacity, we simply add more shards, increasing total capacity. The boxes we add can be any size from small 1U servers to 100 TB monsters; we can mix the two if we wanted. From the application's point of view, there are only shards with a certain amount of free space. This does add some new requirements to your application, however, with the management of individual shards. Each machine that needs read or write access to the storage needs to have all of the shards mounted in some way. For a setup with 20 web servers and 20 storage shards, we'd need 400 open NFS mounts. When a shard fails, we need to deal cleanly with failover, making sure we stop trying to write data to it. At the same time, we need to deal with redundancya machine dying should not cause a portion of our dataset to disappear. The quickest way to achieve redundancy is by synchronously writing two or more copies of every file and failing over to reading a different copy of the shard when a machine dies. Your application will also need to deal with running out of space, a special type of machine "failure." Depending upon the machine and filesystem, you might see massive performance reduction when your disks reach 90, 95, or 98 percent capacity. It's worth benchmarking I/O as you fill up a disk to know what the working limit of your particular hardware is. Your application should be able to deal with marking a shard as non-writable when it reaches a predetermined limit to allow failover to shards with more free space. This is a fairly complicated and specific set of requirements and probably doesn't belong in our core application logicall we care about there is being able to store and retrieve files. We can abstract our storage system into a separate layer, as shown in Figure 9-19, giving our core application a simple interface to the federated shards below. Figure 9-19. Abstracting storage into an additional layer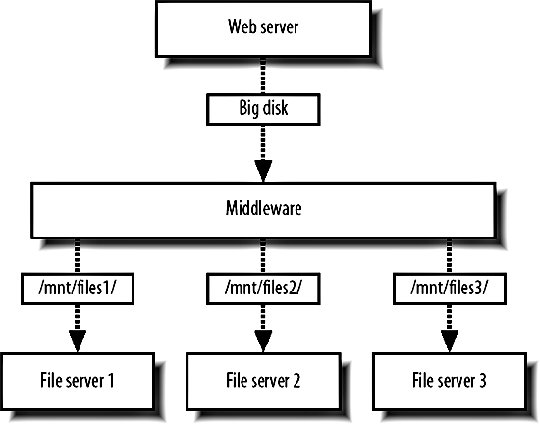 The interface between the middleware layer and the web servers (or whoever is reading and writing) then presents a very simple file storage API with methods to store, replace, and delete files. Storage operations return the shard used, while the other operations require a shard number to operate on. The storage layer deals with all of the space allocation, failover for full shards, failover for dead shards, and journaling for the easy restoration of once-dead shards. This is very similar to the methods used by the Google File System (GFS). We have a central controlling master server or set of servers, which perform the allocation and provides abstraction. Our database acts as the metadata cluster, storing the location and any other needed data about the files, while our shards act as the "chunk" servers, storing the real data in mirrored redundant sets. There are existing products that perform similar roles to this system, including MogileFS (http://www.danga.com/mogilefs/), which implements server and client component software and uses an HTTP interface. 9.9.5. CachingTo get a boost in performance for a given component, we can often stick a cache in front of it to reduce read requests. This is at its core a performance issue, but creeps into scaling as a way to expand the capacity of a component without having to have to design it to be linearly scalable. If we can reduce the usage on a component by five times, we can scale up to five times the traffic without having to change the component at all. This can be very useful for components that are hard to scalewe avoid the scaling issue altogether (at least for a while) until we reach the new capacity limit. Almost any component that we're reading data from can be scaled up by using a cache. Even if the cache doesn't buy us much of a gain in speed (and for very fast systems, it might actually slow us down), by reducing load on the backend and designing a scalable cache, we get a gain in capacity, which is our goal since in the long term. Since caching can occur at any level, we can use many different products and techniques to create a scalable cache. We'll look at only the two common caches, but it's worth bearing in mind that other solutions are readily available. 9.9.6. Caching DataWe've already talked about memcached a fair amount. As a general data cache, memcached allows us to store whatever kind of items we need to, mixing scalar values, database rows, objects, and anything else we can think of. memcached and other simple memory caches put a lot of the responsibility for caching objects on the client end. To read an object, we need to check the cache and possibly perform a request from the source component, caching the result for future requests. As a general purpose cache, we can use memcached for caching all sorts of data inside our application in a single cluster of servers. By using the same component for the caching of several others, we need only solve the integration problems once, with one common entry point for reading and writing cached content. We also reduce the administration overhead by simplifying our setup. Instead of having several clusters with different configurations and requirements, we have a single cluster of identical machines. This also means we get more out of our hardware, which is especially important early on when budgets are tight. Instead of needing two machines for each of five different clusters (e.g., database cache, remote web page cache, temporary calculation results cache, etc.), we can combine them into a single cluster of less machines. If each cache needs only half a server to operate (and requires redundancy), we don't end up in a situation where we're wasting a whole bunch of boxes. Instead of the previous 10, we can now operate all caches on 4 boxes, 3 to handle the load of all 5 caches and 1 extra for redundancy. By combining caches, we can combine the overhead from each of the smaller caches into one large overhead that we can then reduce without losing redundancy. It's not just intermediate data we can store in a cache, either, but final processed data. If we have pages in our application that require intensive calculation, or simply don't get invalidated very often, we can cache chunks of the final HTML in memcached. Typically, in a dynamic application you'll need to show user-specific data on each pageat the least the login statusbut if we cache the invariant portions of the page, we can avoid rendering the hard stuff for every page request. For applications that output the same data using several different templates, we can cache the template environment just before rendering. In Smarty, this involves saving the $smarty object just before we call display( ). For future page requests, we then fetch the object from cache, unthaw it, and call whatever rendering function we need to. Thinking about caching at all levels of the application, especially the layers closer to the final output, can increase the utility of a cache, driving down the cost of other components. 9.9.7. Caching HTTP RequestsSquid (http://www.squid-cache.org/) operates as both a web caching proxy server and a reverse HTTP accelerator proxy. The latter is the one we're concerned withas a reverse proxy, it proxies traffic for a certain set of servers from all clients, rather than proxying data for all servers for a set of clients. By adding a caching reverse proxy, client requests for a resource hit the cache. If there's a cache miss, the cache passes the request on to the original source component. Unlike most memory caches, Squid acts as a complete readthrough cache. Clients only need to hit the cache to get a copy of the resource, either a copy from the cache or a copy from the original source that is automatically cached. The lack of needed logic on the client gives us the benefit of being able to use Squid to cache resources for user agents rather than just internally within our system. Requests from clients don't know and don't care whether a hit is coming from cache or from the backend; it all looks exactly the same. By using the readthrough model, we can also use a Squid cache internally without having to add cache-checking logic, which decreases coupling, increases abstraction and simplicity, and allows us to swap a cache in and out without any changes to the client code. The reading of a Squid cache is controlled solely over HTTP by executing GET commands, which also implicitly triggers a write command as necessary. To allow the ability to explicitly remove objects from cache, Squid allows the PURGE HTTP method. By executing a PURGE just as you would a GET, you can remove an object from cache before it expires or churns: PURGE /459837458973.dat HTTP/1.1 Host: cache.myapp.com HTTP/1.0 200 OK Server: squid/2.5.STABLE10 Mime-Version: 1.0 Date: Fri, 02 Dec 2005 05:20:12 GMT Content-Length: 0 This is particularly useful if you have content that generally doesn't change. You can then tell Squid that the content expires in several years time, so that it remains cached forever. If you need to change or delete the content, you then PURGE it from the cache, forcing Squid to re-cache it next time a client requests it. You can find out more than you could possibly want to about using Squid in Duane Wessels's book Squid: The Definitive Guide (O'Reilly). 9.9.8. Scaling in a NutshellWhile there's been a fair amount of detail in this chapter, you may find it useful to bear these few simple rules in mind when designing a system to be scalable:
Beyond the basic principles, use common sense when scaling an application. Your application can only scale as well as the worst component in it. Identify bottlenecks, design with scaling in mind, and keep a close eye on what's happening in production. To achieve the latter, we're going to need to develop a good monitoring infrastructure, so we'll be looking at techniques for data collection, aggregation, and display in the next chapter. |