Hack 81. Content Filter Without Your Smart Friend Noticing
Hide a content filter in Firefox's core to make web sites vanish like Ninjas in the dark. Blocking access to certain web sites is a common project, whether to protect one's children from the perceived dangers of the Internet or as an April fool's joke for a coworker or friend. Unfortunately, most existing methods fall short in one of two areas. On the one hand, they might be too blatant in their approach, as with most proxy-based solutions, serving up a honking "this page has been blocked" replacement page instead of the requested site. On the other hand, the hosts file is hard to keep secure and safe from tampering. By injecting a few lines of code into Firefox's core, we can get a subtle, effective, and almost undetectable way of preventing the browser from visiting less-than-desirable sites. As a bonus, we can even trick the unlucky user into thinking that the problem lies on the remote server's end rather than the user's. 7.8.1. Starting PointsThe setup for this hack will be virtually identical to disabling Firefox menus [Hack #77], except this time, we'll be editing the JavaScript code in browser.js instead of the frontend UI code in browser.xul. The first step remains the same: identify the code we'll be targeting. We want our code to run between the point where the user enters a URL into the Location bar and the point where Firefox begins actually loading the entered URL. Thus, our search begins at the Location bar. Open a new Firefox window and type about:blank
into the Location bar. Then, open the DOM Inspector from the Tools
menu. Choose File Figure 7-10. Starting point for the hack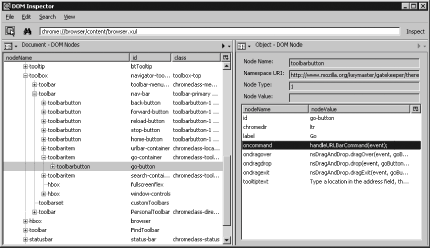 7.8.2. Finding the Files to HackThe key nugget extracted from that foray into the DOM Inspector was a single function name: handleURLBarCommand. If we had absolutely no idea where that function was actually declared, we could use LXR (http://lxr.mozilla.org/aviarybranch/) to search through the entire Firefox code base and find any references to that string. One thing to note about LXR is that the paths it returns are not chrome:// URLs, but rather are reflective of the way the code is organized before compilation and packaging. LXR says that the function we're interested in is defined in /browser/base/content/browser.js, rather than chrome://browser/content/browser.js. However, we're smart enough to know that there aren't too many browser.js files used by Firefox. Sure enough, entering chrome://browser/content/browser.js into the Location bar presents us with a plain-text JavaScript file, confirming our hunch. We'll be using LXR a bit more later on, so we'll keep using Firefox to gather all the pieces necessary for our hack. The actual handleURLBarCommand function is shortcontaining less than 10 lines of actual code. The last line is another function call: BrowserLoadURL(aTriggeringEvent, postData.value);. This new function is declared earlier in browser.js. It's longer and more confusing, but again, there's one promising-looking function call: loadURI. This function is called many times in browser.js, so it will be easiest to go straight to the function declaration by searching for function loadURI. This function is the shortest of the bunch, but it's the end of the yellow brick roadwhere the magic happens. loadURI calls what looks like a JavaScript function, but it's actually linked to the C++ XPCOM code that does the real heavy lifting in Firefox, and C++ is too heavyweight for a quick chrome hack. 7.8.3. Coding OptionsIn any case, we've now found a host function for our stealth code. What should we actually do? The simplest solution is to simply return early from the function, before the XPCOM code gets a chance to run. Unfortunately, that wouldn't create a very convincing spoof of a connection error. Instead, we'll emulate Firefox's behavior for web sites that appear not to exist. Try entering does.not.exist into the Location bar; Firefox will change the cursor and the status bar text ("Looking up does.not.exist"), wait a second or so, and then pop a dialog saying "does.not.exist could not be found. Please check the name and try again," along with a change of the status bar text to "Done." For simplicity, we'll ignore the cursor change and just do the status bar and dialog. In fact, we might not actually want to downright block the web site. For some sites, such as http://www.whitehouse.com or http://www.fafsa.com, we'd rather just automatically redirect the browser to the correct web sites (http://www.whitehouse.gov and http://www.fafsa.ed.gov, respectively.) Thus, instead of just a blacklist, we could also have a redirect list that contains mappings of "bad" sites to good sites. Another alternative direction for the hack to take would be to make the URL bar more forgiving of typing errors in the Location bar, such as treating firefox,com as firefox.com. With that many features, though, the code is more deserving of a full extension rather than just a quick chrome hack. All right, enough features, already. We'll keep it simple and then get down and dirty! 7.8.4. Quick-and-Dirty String ChangesThe "correct" way to access strings from JavaScriptespecially strings shipped with the browseris to use property files and Mozilla stringbundles. However, since this hack will vanish if the browser is upgraded, we can get away with hardcoding the strings instead of fetching them from a stringbundle. This saves us from having to modify browser.xul in addition to browser.js, and it makes our end code a little clearer to read. Speaking of which, all this talk translates in only a few measly lines of changed code. Here's the loadURI function before we hack it: function loadURI(uri, referrer, postData)
{
try {
if (postData === undefined)
postData = null;
getWebNavigation( ).loadURI(uri, nsIWebNavigation.LOAD_FLAGS_NONE,
referrer, postData, null);
} catch (e) {
}
}Here's how the function looks after we hack it: function loadURI(uri, referrer, postData)
{
try {
if (postData === undefined)
postData = null;
var blacklist = /fafsa\.com|whitehouse\.com/;
if (blacklist.test(uri)) {
window.status = 'Looking up ' + uri;
var s = 'The connection was refused when attempting to contact ' + uri;
setTimeout( function(s) { window.status = 'Done'; alert(s); }, 1337, s);
}
else {
getWebNavigation( ).loadURI(uri, nsIWebNavigation.LOAD_FLAGS_NONE,
referrer, postData, null);
}
} catch (e) {
}
}
In any case, our additions begin at var and end at else. The first line declares our blacklist--a regular expression with a number of web site names separated by a pipe character (|), which is the equivalent of a logical OR operator. The dots are escaped (\.) because in regular expressions, the dot is a special character that can mean any character at all. The second line simply checks the URL to be loaded against the blacklist. http://mozilla.org/ would be allowed to pass and load normally (test() returns false), whereas http://www.whitehouse.com would trigger the blacklist and cause our code to be executed. The first two lines of the blocking code are straightforward, but the third deserves a closer look. The setTimeout() function of the window object is JavaScript's way of scheduling asynchronous code execution. It's usually passed a string of code to execute after some number of milliseconds, but it can also take a function as the first argument. This function's arguments are whatever is passed to setTimeout after the time delay; we pass the string to be displayed in an alert dialog. 7.8.5. Wrapping UpIt's time to wrap up this hack. Make sure Firefox isn't running, and then zip up the content directory into browser.jar and move it into the top-level chrome folder, making sure you back up the last version first. If necessary, refer back to [Hack #77] for a memory jogger. Now, when a user enters whitehouse.com in the Location bar, the three lines of code together will set the window status to "Looking up whitehouse.com,"; then, a cool second or so later, they will reset the status bar to "Done" and alert the user that "The connection was refused when attempting to contact whitehouse.com." Whatever page the browser was looking at before whitehouse.com was entered in the Location bar will remain undisturbed. To the user, it'll look just like http://www.whitehouse.com is down; they'll be none the wiser as to what's actually going on. Ben Karel |
 Inspect Window
Inspect Window