|
|
< Day Day Up > |
|
8.3 Cluster PartitioningAs noted earlier, Figure 8-1 is a common setup for many web sites. While that architecture provides a good starting point, the time may come when you want to squeeze more performance out of your replication setup. Partitioning is often the next evolutionary step as the system grows. In this section, we'll look at several related partitioning schemes that can be applied to most load-balanced MySQL clusters. 8.3.1 Role-Based PartitioningMany applications using a MySQL backend do so in different roles. Let's consider a large community web site for which users register and then exchange messages and participate in discussions online. From the data storage angle, several features must be implemented for the site to function. For example, the system must store and retrieve records for individual users (their profiles) as well as messages and message-related metadata. At some point, you decide to add a search capability to the site. Over the past year, you've accumulated a ton of interesting data, and your users want to search it. So you add full-text indexes to the content and offer some basic search facilities. What you soon realize is that the search queries behave quite a bit differently from most of the other queries you run. They're really a whole new class of queries. Rather than retrieving a very small amount of data in a very specific way (fetching a message based on its ID or looking up a user based on username), search queries are more intensive; they take more CPU time to execute. And the full-text indexes are quite a bit larger than your typical MyISAM indexes. In a situation like this, it may make sense to split up the responsibility for the various classes of queries you're executing. Users often expect a search to take a second or two to execute, but pulling up a post or a user page should always happen instantly. To keep the longer-running search queries from interfering with the "must be fast" queries, you can break the slaves into logical subgroups. They'll all still be fed by the same master (for now), but they will be serving in more narrowly focused roles. Figure 8-2 shows a simple example of this with the top half of the diagram omitted. There need not be two physically different load balancers involved. Instead, think of those as logical boxes rather than physical. Most load-balancing hardware can handle dozens of backend clusters simultaneously. Figure 8-2. Partitioning based on role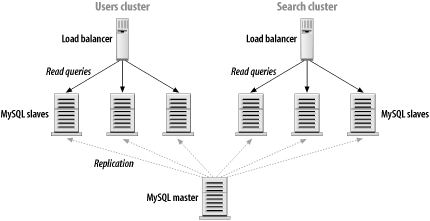 With this separation in place, it's much easier to match the hardware to the task at hand. Queries sent to the user cluster are likely to be I/O bound rather taxing the CPU. They're mainly fetching a few random rows off disk over and over. So maybe it makes sense to spend less money on the CPUs and invest a bit more in the disks and memory (for caching). Perhaps RAID 0 is a good choice on these machines. The search cluster, on the other hand, spends far more CPU time looking through the full-text indexes to match search terms and ranking results based on their score. The machines in this group probably need faster (or dual) CPUs and a fair amount of memory. This architecture is versatile enough to handle workload splitting for a variety of applications. Anytime you notice an imbalance among the types of queries, consider whether it might be worthwhile to split your large cluster into a cluster made up of smaller groups based on a division of labor. 8.3.2 Data-Based PartitioningSome high-volume applications have surprisingly little variety in the types of queries they use. Partitioning across roles isn't effective in these cases, so the alternative is to partition the data itself and put a bit of additional logic into the application code. Figure 8-3 illustrates this. Figure 8-3. Partitioning based on data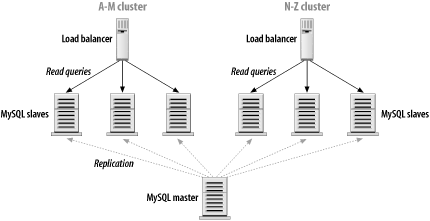 In an application that deals with fetching user data from MySQL, a simple partitioning scheme is to use the first character of the username. Those beginning with letters A-M reside in the first partition. The other partition handles the second half of the alphabet. The additional application logic is simply a matter of checking the username before deciding which database connection to use when fetching the data. The choice of splitting based on an alphabetic range is purely arbitrary. You can just as easily use a numeric representation of each username, sending all users with even numbers to one cluster and all odd numbers to the other. Volumes have been written on efficient and uniform hashing functions that can be used to group arbitrarily large volumes of data into a fixed number of buckets. Our goal isn't to recommend a particular method but to suggest that you look at the wealth of existing information and techniques before inventing something of your own. 8.3.3 Filtering and Multicluster PartitioningAssuming that the majority of activity is read-only (that is, on the slaves), the previous partitioning solutions scale well as the demand on a high-volume application increases. But what happens when a bottleneck develops on the master? The obvious solution is to upgrade the master. If it is CPU-bound, add more CPU power. If it's I/O bound, add faster disks and more of them. There's a flaw in that logic, however. If the master is having trouble keeping up with the load, the slaves will be under at least as much stress. Remember that MySQL's replication is query based. The volume of write queries handled by the slaves is usually identical to that handled by the master. If the master can no longer keep up, odds are that the slaves are struggling just as much. 8.3.3.1 FilteringAn easy solution to the problem is filtering. As described in Chapter 7, MySQL provides the ability to filter the replication stream selectively on both the master and the slave. The problem is that you can filter based only on database or table names. Filtering is therefore not an option if you use data-based partitioning. MySQL has no facility to filter based on the queries themselves, only the names of the databases and tables involved. Filtering may work well in a role-based partitioning setup in which the various slave clusters don't need full copies of the master's data (for instance, where a search cluster needs two particular tables, and the user cluster needs the other four). If you use role-based partitioning, it's probably worthwhile to set up each cluster to replicate only the tables or databases the cluster needs to do its job. The filtering must be on the slaves themselves, as opposed to the master, so the slaves' IO thread will still copy all the master's write queries. However, the SQL thread will read right past queries the slaves aren't interested in (those that are filtered out). 8.3.3.2 Separate clustersAside from Moore's Law, the only real solution to scaling the write side with this model is to use truly separate clusters. By going from a single master with many slaves to several independent masters with their own slaves, you eliminate the bottlenecks associated with a higher volume of write activity, and you can get away with using less expensive hardware. Figure 8-4 illustrates this logical progression. As before, there are two groups of slaves, one for search and one for user lookups, but this time each group is served by its own master. Figure 8-4. Multicluster partitioning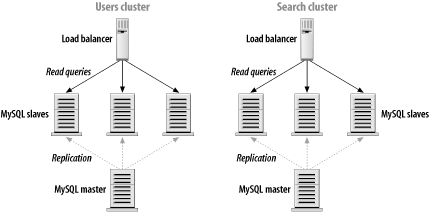 |
|
|
< Day Day Up > |
|