| only for RuBoard - do not distribute or recompile |
This section presents an example of a common web transaction, showing the HTTP exchanged between the client and server program.
Given the following URL:
http://hypothetical.ora.com:80/
The browser interprets the URL as follows:
Use HTTP, the Hypertext Transfer Protocol.
Contact a computer over the network with the hostname of hypothetical.ora.com.
Connect to the computer at port 80. The port number can be any legitimate IP port number: 1 through 65535, inclusively.[1] If the colon and port number are omitted, the port number is assumed to be HTTP's default port number, which is 80.
[1] Assuming IP version 4 addressing, which is the most common version of IP currently in use.
Anything after the hostname and optional port number is regarded as a document path. In this example, the document path is /.
So the browser connects to hypothetical.ora.com on port 80 using the HTTP protocol. The message that the browser sends to the server is:
GET / HTTP/1.1
Accept: image/gif, image/x-xbitmap, image/
jpeg, image/pjpeg, */*
Accept-Language: en-us
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE
5.01; Windows NT)
Host: hypothetical.ora.com
Connection: Keep-Alive
Let's look at what these lines are saying:
The first line of this request (GET / HTTP/1.1) requests a document at / from the server. HTTP/1.1 is given as the version of the HTTP protocol that the browser uses.
The second line tells the server what kind of documents are accepted by the browser.
The third line indicates that the preferred language is English. This header allows the client to specify a preference for one or more languages, in the event that a server has the same document in multiple languages.
The fourth line indicates that the client understands how to interpret a server response that is compressed with the gzip or deflate algorithm.
In the fifth line, beginning with the string User-Agent, the client identifies itself as Mozilla version 4.0, running on Windows NT. In parenthesis it mentions that it is really Microsoft Internet Explorer version 5.01.
The sixth line tells the server what the client thinks the server's hostname is. This header is mandatory in HTTP 1.1, but optional in HTTP 1.0. Since the server may have multiple hostnames, the client indicates which hostname is being requested. In this environment, a web server can have a different document tree for each hostname assigned to it. If the client hasn't specified the server's hostname, the server may be unable to determine which document tree to use.
The seventh line (Connection:) tells the server to keep the TCP connection open until explicitly told to disconnect. Under HTTP 1.1, the default server behavior is to keep the connection open until the client specifies that the connection should be closed. The standard behavior in HTTP 1.0 is to close the connection after the client's request. See the discussion in Section 1.13 later in this book for details.
Together, these seven lines constitute a request. Lines two through seven are request headers. Section 1.5 discusses each header in more detail.
Given a request like the one previously shown, the server looks for the server resource associated with "/" and returns it to the browser, preceding it with header information in its response. The resource associated with the URL depends on how the server is implemented. It could be a static file or it could be dynamically generated. In this case, the server returns:
HTTP/1.1 200 OK Date: Mon, 06 Dec 1999 20:54:26 GMT Server: Apache/1.3.6 (Unix) Last-Modified: Fri, 04 Oct 1996 14:06:11 GMT ETag: "2f5cd-964-381e1bd6" Accept-Ranges: bytes Content-length: 327 Connection: close Content-type: text/html <title>Sample Homepage</title> <img src="/images/oreilly_mast.gif"> <h1>Welcome</h1> Hi there, this is a simple web page. Granted, it may not be as elegant as some other web pages you've seen on the net, but there are some common qualities: <ul> <li> An image, <li> Text, <li> and a <a href="/example2.html"> hyperlink. </a> </ul>
If you look at this response, you'll see it begins with a series of lines that specify information about the document and about the server itself. After a blank line, it returns the document. Lines 2-9 are called the response header, and the part after the first blank line is called the body or entity, or entity-body. Let's look at the header information:
The first line, HTTP/1.1 200 OK, tells the client what version of the HTTP protocol the server uses. But more importantly, by returning a status code of 200, it says that the document has been found and will transmit the document in its response.
The second line indicates the current date on the server. The time is expressed in Greenwich Mean Time (GMT).
The third line tells the client what kind of software the server is running. In this case, the server is Apache version 1.3.6 on Unix.
The fourth line specifies the most recent modification time of the document requested by the client. This modification time is often used for caching purposesso a browser may not need to request the entire HTML file again if its modification time doesn't change
The fifth line indicates an entity tag. This provides the web client with a unique identifier for the server resource. It is highly unlikely for two different server resources to have the same entity tag. This tag provides a powerful mechanism for caching.
The sixth line indicates to the browser that the server possesses the ability to return subsections of a document, instead of returning the entire document every time it is requested. This is useful for retrieving records in a document, which may be useful for database and streaming multimedia applications.
The seventh line tells the client how many bytes are in the entity body that follow the headers. In this case, the entity body is 327 bytes long.
The eighth line indicates that the connection will close after the server's response. If the client wants to send another request, it will need to open another connection to the server.
The ninth line (Content-type) tells the browser what kind of document the server is including in its response. In this case, it's HTML.
After all this information, a blank line and the document text follow. Figure 1.1 shows the transaction.
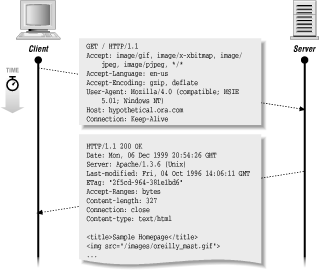
The document is in HTML (as promised in the Content-type line). The browser retrieves the document and then formats it as neededfor example, each <li> item between the <ul> and </ul> is printed as a bullet and indented, the <img> tag displays a graphic on the screen, etc.
To process the image tag, the browser actually initiates a second HTTP request to retrieve the image. When the server returns the image, it includes a Content-type header indicating the format of the image (e.g., image/gif). From the declared content type, the browser knows what kind of image it will receive and can render it as required. The browser shouldn't guess the content type based on the document path; it is up to the server to tell the client.
The important thing to note is that the HTML formatting and image rendering are done at the browser end. All the server does is return documents; the browser is responsible for how they look to the user.
To generalize, all client requests and server responses follow the same general structure shown in Figure 1.1.
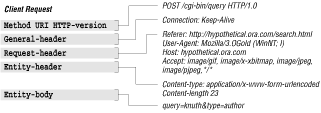
Figure 1.2 shows the structure of a client request.
HTTP transactions do not need to use all the headers. As a matter of fact, it is possible to perform some HTTP requests without supplying any header information at all. For example, in the most simple case, a request of GET / HTTP/1.0 without any headers is sufficient for most servers to understand the client.[2]
[2] Use of HTTP 1.1 is encouraged over 1.0. In the case of HTTP 1.1, a GET / HTTP/1.1 with a Host header is the minimal amount of information needed for an HTTP 1.1 request.
HTTP requests have the following general components:
The first line tells the client which method to use, which entity (document) to apply it to, and which version of HTTP the client is using. Possible HTTP 1.1 methods are GET, POST, HEAD, PUT, LINK, UNLINK, DELETE, OPTIONS, and TRACE. HTTP 1.0 does not support the OPTIONS or TRACE method. Not all methods need be supported by a server.
The URL specifies the location of a document to apply the method to. Each server may have its own way of translating the URL string into some form of usable resource. For example, the URL may represent a document to transmit to the client. Or the URL may actually map to a program, the output of which is sent to the client.
Finally, the last entry on the first line specifies the version of HTTP the client is using.
General message headers are optional headers used in both the client request and server response. They indicate general information such as the current time or the path through a network that the client and server are using.
Request headers tell the server more information about the client. The client can identify itself and the user to the server, and specify preferred document formats that it would like to see from the server.
Entity headers are used when an entity (a document) is about to be sent. They specify information about the entity, such as encoding schemes, length, type, and origin.
Now for server responses. Figure 1.3 maps out the structure of a server response.
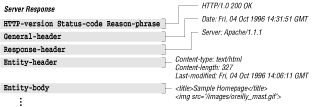
In the server response, the general header and entity headers are the same as those used in the client request. The entity-body is like the one used in the client request, except that it is used as a response.
The first part of the first line indicates the version of HTTP the server is using. The server will make every attempt to conform to the most compatible version of HTTP that the client is using. The status code indicates the result of the request, and the reason phrase is a human-readable description of the status code.
The response header tells the client about the configuration of the server. It informs the client of the methods that are supported, requests authorization, or tells the client to try again later.
| only for RuBoard - do not distribute or recompile |