|
|
< Day Day Up > |
|
4.1 HTTPThe Hypertext Transport Protocol (HTTP) is the lingua franca of the web. In order to develop any type of web application, you must understand at least the basics of this protocol. Before we dig into servlets and JSP, let's see what HTTP is all about. HTTP is based on a very simple communications model. Here's how it works: a client, typically a web browser, sends a request for a resource to a server, and the server sends back a response corresponding to the resource (or a response with an error message if it can't process the request for some reason). A resource can be a number of things, such as a simple HTML file returned verbatim to the browser or a program that generates the response dynamically. The request/response model is illustrated in Figure 4-1. Figure 4-1. HTTP request/response with two resources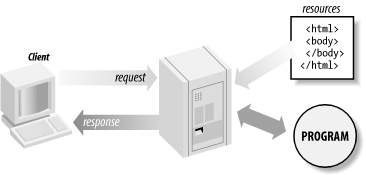 This simple model implies three important facts you must be aware of:
Over the years, people have developed various tricks to overcome HTTP's stateless naturethe first problem. JSF uses these tricks behind the scenes, so you rarely need to worry about it, but we'll look at how it's done later. The other two problemsno immediate feedback and no details about how the request is madeare harder to deal with, but some amount of interactivity can be achieved by generating a response that includes client-side code (code executed by the browser), such as JavaScript or a Java applet. JSF user interface components can generate this code for you. 4.1.1 Requests in DetailLet's take a closer look at requests. A user sends a request to the server by clicking a link on a web page, submitting a form, or typing in a web page address in the browser's address field. To send a request, the browser must know which server to talk to and which resource to ask for. This information is specified as a uniform resource locator (URL): http://www.gefionsoftware.com/index.html The first part of the URL shown here specifies that the request be made using the HTTP protocol. This is followed by the name of the server, in this case www.gefionsoftware.com. The web server waits for requests to come in on a specific TCP/IP port. Port number 80 is the standard port for HTTP requests. If the web server uses another port, the URL must specify the port number in addition to the server name. For example: http://www.gefionsoftware.com:8080/index.html This request is sent to a server that uses port 8080 instead of 80. The last part of the URL, /index.html, identifies the resource that the client is requesting. A URL is actually a specialization of a uniform resource identifier (URI, defined in the RFC 2396[1] specification). A URL identifies a resource partly by its location, for instance, the server that contains the resource. Another type of URI is a uniform resource name (URN), a globally unique identifier that is valid no matter where the resource is located. HTTP deals only with the URL variety. The terms URI and URL are often used interchangeably, but unfortunately they have slightly different definitions in different specifications. I'm trying to use the terms as defined by the HTTP/1.1 specification (RFC 2616), which is pretty close to how they are mostly used in the servlet, JSP, and JSF specifications. Hence, I use the term URL only when the URI must start with http (or https, for HTTP over an encrypted connection) followed by a server name and possibly a port number, as in the previous examples. I use URI as a generic term for any string that identifies a resource, where the location can be deduced from the context and isn't necessarily part of the URI. For example, when the request has been delivered to the server, the location is a given, and only the resource identifier is important.
The browser uses the URL information to create the request message and send it to the specified server using the specified protocol. An HTTP request message consists of three things: a request line, some request headers, and possibly a request body. The request line starts with the request method name, followed by a resource identifier and the protocol version used by the browser: GET /index.html HTTP/1.1 The most commonly used request method is named GET. As the name implies, a GET request is used to retrieve a resource from the server. If you type a URL in the browser's address field, or click on a link, the request is sent as a GET request to the server. The request headers provide additional information the server may use to process the request. The message body is included only in some types of requests, like the POST request, discussed later. Here's an example of a valid HTTP request message: GET /index.html HTTP/1.1 Host: www.gefionsoftware.com User-Agent: Mozilla/5.0 (Windows; U; Win 9x 4.90; en-US; rv: 1.0.2) Accept: image/gif, image/jpeg, image/pjpeg, image/png, */* Accept-Language : en Accept-Charset : iso-8859-1,*,utf-8 The request line specifies the GET method and asks for the resource named /index.html to be returned using the HTTP/1.1 protocol version. The various headers provide additional information. The Host header tells the server the hostname used in the URL. A server may have multiple names, so this information is used to distinguish between multiple virtual web servers sharing the same web server process. The User-Agent header contains information about the type of browser making the request. The server can use this to send different types of responses to different types of browsers. For instance, if the server knows whether Internet Explorer or Netscape Navigator is used, it can send a response that takes advantage of each browser's unique features. It can also tell if a client other than an HTML browser is being used, such as a Wireless Markup Language (WML) browser on a cell phone or a PDA device, and generate an appropriate response. The Accept headers provide information about the languages and file formats the browser accepts. These headers can be used to adjust the response to the capabilities of the browser and the user's preferences, such as using a supported image format and the user's preferred language. These are just a few of the headers that can be included in a request message. The HTTP specification, available at http://www.w3c.org/, describes all of them. The URI doesn't necessarily correspond to a static file on the server. It can identify an executable program, a record in a database, or pretty much anything the web server knows about. That's why the generic term resource is used. In fact, there's no way to tell if the /index.html URI corresponds to a file or something else; it's just a name that means something to the server. The web server is configured to map these unique names to the real resources. 4.1.2 Responses in DetailWhen the web server receives the request, it looks at the URI and decides how to handle it based on configuration information. It may handle the request internally by simply reading an HTML file from the filesystem, or it may forward the request to some component that is responsible for the resource corresponding to the URI. This can be a program that uses database information, for instance, to dynamically generate an appropriate response. To the browser it makes no difference how the request is handled; all it cares about is getting a response. The response message looks similar to the request message. It consists of three things: a status line, some response headers, and an optional response body. Here's an example: HTTP/1.1 200 OK
Last-Modified: Mon, 20 Dec 2002 23:26:42 GMT
Date: Mon, 16 Jun 2003 20:52:40 GMT
Status: 200
Content-Type: text/html
Servlet-Engine: Tomcat Web Server/5.0
Content-Length: 59
<html>
<body>
<h1>Hello World!</h1>
</body>
</html>
The status line starts with the name of the protocol, followed by a status code and a short description of the status code. Here the status code is 200, meaning the request was executed successfully. The response message has headers just like the request message. In this example, the Last-Modified header gives the date and time for when the resource was last modified. The browser can use this information as a timestamp in a local cache; the next time the user asks for this resource, the browser can ask the server to send it only if it's been updated since the last time it was requested. The Content-Type header tells the browser what type of response data the body contains, and the Content-Length header how large it is. The other headers are self-explanatory. A blank line separates the headers from the message body. Here the body is a simple HTML page: <html>
<body>
<h1>Hello World!</h1>
</body>
</html>
Of course, the body can contain a more complex HTML page or any other type of content. For example, the request may return an HTML page with <img> elements. When the browser reads the first response and finds the <img> elements, it sends a new request for the resource identified by each element, often in parallel. The server returns one response for each image request, with a Content-Type header telling what type of image it is (for instance, image/gif) and the body containing the bytes that make up the image. The browser then combines all responses to render the complete page. This interaction is illustrated in Figure 4-2. Figure 4-2. Interaction between a web client and a server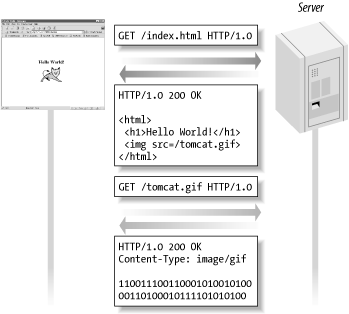 4.1.3 Request ParametersBesides the URI and headers, a request message can contain additional information in the form of parameters. If the URI identifies a server-side program for displaying weather information, for example, request parameters can provide information about which city the user wants to see a forecast for. In an e-commerce application, the URI may identify a program that processes orders, using the customer number and the list of items to be purchased as parameters. Parameters can be sent in one of two ways: tacked on to the URI in the form of a query string or sent as part of the request message body. This is an example of a URL with a query string: http://www.weather.com/forecast?city=Hermosa+Beach&state=CA The query string starts with a question mark (?) and consists of name/value pairs separated by ampersands (&). These names and values must be URL-encoded, meaning that special characters, such as whitespace, question marks, ampersands, and all other nonalphanumeric characters are encoded so that they don't get confused with characters used to separate name/value pairs and other parts of the URI. In this example, the space between Hermosa and Beach is encoded as a plus sign. Other special characters are encoded as their corresponding hexadecimal ASCII value; for instance, a question mark is encoded as %3F. When parameters are sent as part of the request body, they follow the same syntax: URL-encoded name/value pairs separated by ampersands. 4.1.4 Request MethodsAs mentioned earlier, GET is the most commonly used request method, intended to retrieve a resource without causing anything else to happen on the server. The POST method is almost as common as GET. POST requests some kind of processing on the server; for instance, updating a database or processing a purchase order. The way parameters are transferred is one of the most obvious differences between the GET and POST request methods. A GET request always uses a query string to send parameter values, while a POST request sends them as part of the body (it can also send some parameters as a query string, just to make life interesting). If you insert a link in an HTML page using an <a> element, clicking on the link results in a GET request being sent to the server. The GET request uses a query string to pass parameters, so you can include hardcoded parameter values in the link URI: <a href="/forecast?city=Hermosa+Beach&state=CA"> Hermosa Beach weather forecast </a> When you use a form to send user input to the server, you can specify whether to use the GET or POST method with the method attribute, as shown here: <form action="/forecast" method="POST"> City: <input name="city" type="text"> State: <input name="state" type="text"> <p> <input type="SUBMIT"> </form> If the user enters "Hermosa Beach" and "CA" in the form fields and clicks on the Submit button, the browser sends a request message like this to the server: POST /forecast HTTP/1.1 Host: www.gefionsoftware.com User-Agent: Mozilla/5.0 (Windows; U; Win 9x 4.90; en-US; rv: 1.0.2) Accept: image/gif, image/jpeg, image/pjpeg, image/png, */* Accept-language: en-US Accept-charset: iso-8859-1,*,utf-8 city=Hermosa+Beach&state=CA Due to the differences in how parameters are sent by GET and POST requests, as well as the differences in their intended purpose, browsers handle the requests in different ways. A GET request, parameters and all, can easily be saved as a bookmark, hardcoded as a link, and the response cached by the browser. Also, the browser knows that no damage will be done if it needs to send a GET request again automatically; for instance, if the user clicks the Reload button. A POST request, on the other hand, can't be bookmarked as easily; the browser would have to save both the URI and the request message body. A POST request is intended to perform some possibly irreversible action on the server, so the browser must also ask the user if it's okay to send the request again. You have probably seen this type of confirmation dialog, shown in Figure 4-3, numerous times. Figure 4-3. Repost confirmation dialog |
|
|
< Day Day Up > |
|