9.2. Basic MySQL Cluster ConceptsNDB is an in-memory storage engine offering high-availability and data-persistence features. The NDB storage engine can be configured with a range of failover and load-balancing options, but it is easiest to start with the storage engine at the cluster level. MySQL Cluster's NDB storage engine contains a complete set of data, dependent only on other data within the cluster itself. We will now describe how to set up a MySQL Cluster consisting of an NDB storage engine and some MySQL servers. The cluster portion of MySQL Cluster is currently configured independently of the MySQL servers. In a MySQL Cluster, each part of the cluster is considered to be a node. Note: In many contexts, the term "node" is used to indicate a computer, but when discussing MySQL Cluster it means a process. There can be any number of nodes on a single computer, for which we use the term cluster host. There are three types of cluster nodes, and in a minimal MySQL Cluster configuration, there will be at least three nodes, one of each of these types:
For a brief introduction to the relationships between nodes, node groups, replicas, and partitions in MySQL Cluster, see Section 9.2.1, "MySQL Cluster Nodes, Node Groups, Replicas, and Partitions." Configuration of a cluster involves configuring each individual node in the cluster and setting up individual communication links between nodes. MySQL Cluster is currently designed with the intention that storage nodes are homogeneous in terms of processor power, memory space, and bandwidth. In addition, to provide a single point of configuration, all configuration data for the cluster as a whole is located in one configuration file. The management server (MGM node) manages the cluster configuration file and the cluster log. Each node in the cluster retrieves the configuration data from the management server, and so requires a way to determine where the management server resides. When interesting events occur in the data nodes, the nodes transfer information about these events to the management server, which then writes the information to the cluster log. In addition, there can be any number of cluster client processes or applications. These are of two types:
9.2.1. MySQL Cluster Nodes, Node Groups, Replicas, and PartitionsThis section discusses the manner in which MySQL Cluster divides and duplicates data for storage. Central to an understanding of this topic are the following concepts, listed here with brief definitions:
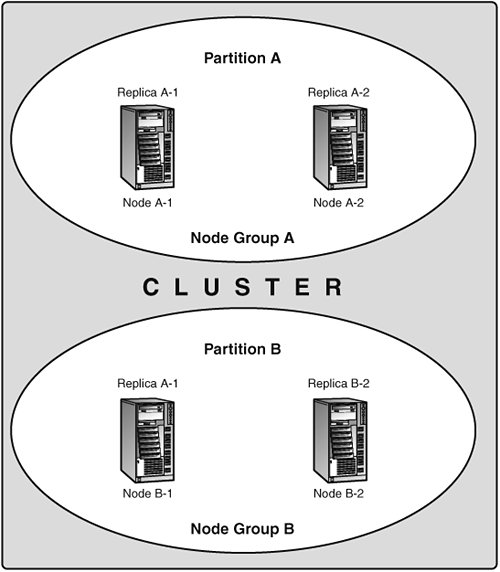
Figure 9.2 illustrates a MySQL Cluster with four data nodes, arranged in two node groups of two nodes each. Note that no nodes other than data nodes are shown here, although a working cluster requires an ndb_mgm process for cluster management and at least one SQL node to access the data stored by the cluster. Figure 9.2. A MySQL Cluster, with two node groups having two nodes each.
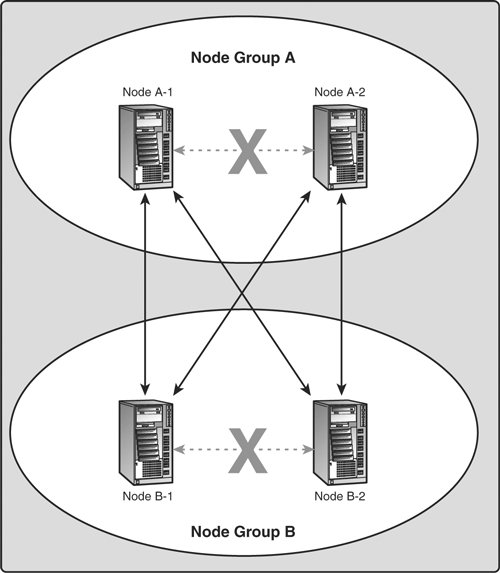
The data stored by the cluster is divided into two partitions, labeled A and B in the diagram. Each partition is storedin multiple copieson a node group. The data making up Partition A is stored on Node A-1, and this data is identical to that stored by Node A-2. The data stored by Nodes B-1 and B-2 is also the samethese two nodes store identical copies of the data making up Partition B. What this means so far as the continued operation of a MySQL Cluster is this: so long as each node group participating in the cluster has at least one "live" node, the cluster has a complete copy of all data and remains viable. This is illustrated in Figure 9.3. Figure 9.3. Nodes required to keep a 2x2 cluster viable.
In this example, where the cluster consists of two node groups of two nodes each, any combination of at least one node in Node Group A and at least one node in Node Group B is sufficient to keep the cluster "alive" (indicated by arrows in the diagram). However, if both nodes from either node group fail, the remaining two nodes are not sufficient (shown by arrows marked out with an X); in either case, the cluster has lost an entire partition and so can no longer provide access to a complete set of all cluster data. |