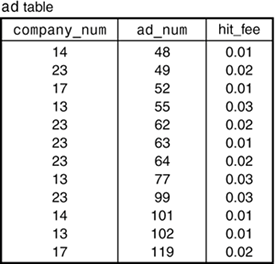
Using IndexingIndexing is the most important tool you have for speeding up queries. Other techniques are available to you, too, but generally the one thing that makes the most difference is the proper use of indexes. On the MySQL mailing list, people often ask for help in making a query run faster. In a surprisingly large number of cases, there are no indexes on the tables in question, and adding indexes often solves the problem immediately. It doesn't always work like that, because optimization isn't always simple. Nevertheless, if you don't use indexes, in many cases you're just wasting your time trying to improve performance by other means. Use indexing first to get the biggest performance boost and then see what other techniques might be helpful. This section describes what an index is and how indexing improves query performance. It also discusses the circumstances under which indexes might degrade performance and provides guidelines for choosing indexes for your table wisely. In the next section, we'll discuss MySQL's query optimizer that attempts to find the most efficient way to execute queries. It's good to have some understanding of the optimizer in addition to knowing how to create indexes because then you'll be better able to take advantage of the indexes you create. Certain ways of writing queries actually prevent your indexes from being useful, and generally you'll want to avoid having that happen. Benefits of IndexingLet's consider how an index works by beginning with a table that has no indexes. An unindexed table is simply an unordered collection of rows. For example, Figure 4.1 shows the ad table that was discussed in Chapter 1, "Getting Started with MySQL and SQL." There are no indexes on this table, so to find the rows for a particular company, it's necessary to examine each row in the table to see if it matches the desired value. This involves a full table scan, which is slow, as well as tremendously inefficient if the table is large but contains only a few records that match the search criteria. Figure 4.1. Unindexed ad table.
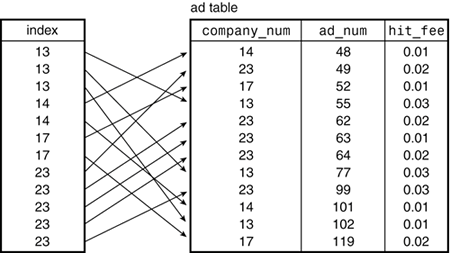
Figure 4.2 shows the same table, but with the addition of an index on the company_num column in the ad table. The index contains an entry for each row in the ad table, but the index entries are sorted by company_num value. Now, instead of searching through the table row by row looking for items that match, we can use the index. Suppose that we're looking for all rows for company 13. We begin scanning the index and find three values for that company. Then we reach the index value for company 14, which is higher than the one we're looking for. Index values are sorted, so when we read the index record containing 14, we know we won't find any more matches and can quit looking. Thus, one efficiency gained by using the index is that we can tell where the matching rows end and can skip the rest. Another efficiency comes about through the use of positioning algorithms for finding the first matching entry without doing a linear scan from the start of the index (for example, a binary search is much quicker than a scan). That way, we can quickly position to the first matching value and save a lot of time in the search. Databases use various techniques for positioning to index values quickly, but it's not so important here what those techniques are. What's important is that they work and that indexing is a good thing. Figure 4.2. Indexed ad table.
You might be asking why we don't just sort the data rows and dispense with the index. Wouldn't that produce the same type of improvement in search speed? Yes, it wouldif the table had a single index. But you might want to add a second index, and you can't sort the data rows two different ways at once. (For example, you might want one index on customer names and another on customer ID numbers or phone numbers.) Using indexes as entities separate from the data rows solves the problem and allows multiple indexes to be created. In addition, rows in the index are generally shorter than data rows. When you insert or delete new values, it's easier to move around shorter index values to maintain the sort order than to move around the longer data rows. The particular details of index implementations vary for different MySQL storage engines. For example, for a MyISAM table, the table's data rows are kept in a data file, and index values are kept in an index file. You can have more than one index on a table, but they're all stored in the same index file. Each index in the index file consists of a sorted array of key records that are used for fast access into the data file. By contrast, the BDB and InnoDB storage engines do not separate data rows and index values in the same way, although both maintain indexes as sets of sorted values. By default, the BDB engine uses a single file per table to store both data and index values. The InnoDB engine uses a single tablespace within which it manages data and index storage for all InnoDB tables. InnoDB can be configured to create each table with its own tablespace, but even so, a table's data and indexes are stored in the same tablespace file. The preceding discussion describes the benefit of an index in the context of single-table queries, where the use of an index speeds searches significantly by eliminating the need for full table scans. Indexes are even more valuable when you're running queries involving joins on multiple tables. In a single-table query, the number of values you need to examine per column is the number of rows in the table. In a multiple-table query, the number of possible combinations skyrockets because it's the product of the number of rows in the tables. Suppose that you have three unindexed tables, t1, t2, and t3, each containing a column i1, i2, and i3, respectively, and each consisting of 1,000 rows that contain the numbers 1 through 1000. A query to find all combinations of table rows in which the values are equal looks like this: SELECT t1.i1, t2.i2, t3.i3 FROM t1, t2, t3 WHERE t1.i1 = t2.i2 AND t2.i1 = t3.i3; The result of this query should be 1,000 rows, each containing three equal values. If we process the query in the absence of indexes, we have no idea which rows contain which values without scanning them all. Consequently, we must try all combinations to find the ones that match the WHERE clause. The number of possible combinations is 1,000 x 1,000 x 1,000 (one billion!), which is a million times more than the number of matches. That's a lot of wasted effort. The example illustrates that as tables grow, the time to process joins on those tables grows even more if no indexes are used, leading to very poor performance. We can speed things up considerably by indexing the tables, because the indexes allow the query to be processed like this:
In this case, we still perform a full scan of table t1, but we can do indexed lookups on t2 and t3 to pull out rows from those tables directly. The query runs about a million times faster this wayliterally. This example is contrived for the purpose of making a point, of course. Nevertheless, the problems it illustrates are real, and adding indexes to tables that have none often results in dramatic performance gains. MySQL uses indexes in several ways:
Costs of IndexingIn general, if MySQL can figure out how to use an index to process a query more quickly, it will. This means that, for the most part, if you don't index your tables, you're hurting yourself. You can see that I'm painting a rosy picture of the benefits of indexing. Are there disadvantages? Yes, there are. There are costs both in time and in space. In practice, these drawbacks tend to be outweighed by the advantages, but you should know what they are. First, indexes speed up retrievals but slow down inserts and deletes, as well as updates of values in indexed columns. That is, indexes slow down most operations that involve writing. This occurs because writing a record requires writing not only the data row, it requires changes to any indexes as well. The more indexes a table has, the more changes need to be made, and the greater the average performance degradation. In the section "Loading Data Efficiently," we'll go into more detail about this phenomenon and what you can do about it. Second, an index takes up disk space, and multiple indexes take up correspondingly more space. This might cause you to reach a table size limit more quickly than if there are no indexes:
The practical implication of both these factors is that if you don't need a particular index to help queries perform better, don't create it. Choosing IndexesThe syntax for creating indexes is covered in the section "Creating Indexes," of Chapter 2, "MySQL SQL Syntax and Use." I assume here that you've read that section. But knowing syntax doesn't in itself help you determine how your tables should be indexed. That requires some thought about the way you use your tables. This section gives some guidelines on how to identify candidate columns for indexing and how best to set up indexes: Index columns that you use for searching, sorting, or grouping, not columns you only display as output. In other words, the best candidate columns for indexing are the columns that appear in your WHERE clause, columns named in join clauses, or columns that appear in ORDER BY or GROUP BY clauses. Columns that appear only in the output column list following the SELECT keyword are not good candidates:
SELECT
col_a The columns that you display and the columns you use in the WHERE clause might be the same, of course. The point is that appearance of a column in the output column list is not in itself a good indicator that it should be indexed. Columns that appear in join clauses or in expressions of the form col1 = col2 in WHERE clauses are especially good candidates for indexing. col_b and col_c in the query just shown are examples of this. If MySQL can optimize a query using joined columns, it cuts down the potential table-row combinations quite a bit by eliminating full table scans. Consider column cardinality. The cardinality of a column is the number of distinct values that it contains. For example, a column that contains the values 1, 3, 7, 4, 7, and 3 has a cardinality of four. Indexes work best for columns that have a high cardinality relative to the number of rows in the table (that is, columns that have many unique values and few duplicates). If a column contains many different age values, an index will differentiate rows readily. An index will not help for a column that is used to record sex and contains only the two values 'M' and 'F'. If the values occur about equally, you'll get about half of the rows whichever value you search for. Under these circumstances, the index might never be used at all, because the query optimizer generally skips an index in favor of a full table scan if it determines that a value occurs in a large percentage of a table's rows. The conventional wisdom for this percentage used to be "30%." Nowadays the optimizer is more complex and takes other factors into account, so the percentage is not the sole determinant of when MySQL prefers a scan over using an index. Index short values. Use smaller data types when possible. For example, don't use a BIGINT column if a MEDIUMINT is large enough to hold the values you need to store. Don't use CHAR(100) if none of your values are longer than 25 characters. Smaller values improve index processing in several ways:
For the InnoDB and BDB storage engines that use clustered indexes, it's especially beneficial to keep the primary key short. A clustered index is one where the data rows are stored together with (that is, clustered with) the primary key values. Other indexes are secondary indexes; these store the primary key value with the secondary index values. A lookup in a secondary index yields a primary key value, which then is used to locate the data row. The implication is that primary key values are duplicated into each secondary index, so if primary key values are longer, the extra storage is required for each secondary index as well. Index prefixes of string values. If you're indexing a string column, specify a prefix length whenever it's reasonable to do so. For example, if you have a CHAR(200) column, don't index the entire column if most values are unique within the first 10 or 20 characters. Indexing the first 10 or 20 characters will save a lot of space in the index, and probably will make your queries faster as well. By indexing shorter values, you gain the advantages described in the previous item relating to comparison speed and disk I/O reduction. You want to use some common sense, of course. Indexing just the first character from a column isn't likely to be that helpful because then there won't be very many distinct values in the index. You can index prefixes of CHAR, VARCHAR, BINARY, VARBINARY, BLOB, and TEXT columns. The syntax is described in "Creating Indexes," in Chapter 2. Take advantage of leftmost prefixes. When you create an n-column composite index, you actually create n indexes that MySQL can use. A composite index serves as several indexes because any leftmost set of columns in the index can be used to match rows. Such a set is called a "leftmost prefix." (This is different from indexing a prefix of a column, which is using the first n characters of the column for index values.) Suppose that you have a table with a composite index on columns named state, city, and zip. Rows in the index are sorted in state/city/zip order, so they're automatically sorted in state/city order and in state order as well. This means that MySQL can take advantage of the index even if you specify only state values in a query, or only state and city values. Thus, the index can be used to search the following combinations of columns: state, city, zip state, city state MySQL cannot use the index for searches that don't involve a leftmost prefix. For example, if you search by city or by zip, the index isn't used. If you're searching for a given state and a particular ZIP code (columns 1 and 3 of the index), the index can't be used for the combination of values, although MySQL can narrow the search using the index to find rows that match the state. Don't over-index. Don't index everything in sight based on the assumption "the more, the better." That's a mistake. Every additional index takes extra disk space and hurts performance of write operations, as has already been mentioned. Indexes must be updated and possibly reorganized when you modify the contents of your tables, and the more indexes you have, the longer this takes. If you have an index that is rarely or never used, you'll slow down table modifications unnecessarily. In addition, MySQL considers indexes when generating an execution plan for retrievals. Creating extra indexes creates more work for the query optimizer. It's also possible (if unlikely) that MySQL will fail to choose the best index to use when you have too many indexes. Maintaining only the indexes you need helps the query optimizer avoid making such mistakes. If you're thinking about adding an index to a table that is already indexed, consider whether the index you're thinking about adding is a leftmost prefix of an existing multiple-column index. If so, don't bother adding the index because, in effect, you already have it. (For example, if you already have an index on state, city, and zip, there is no point in adding an index on state.) Match index types to the type of comparisons you perform. When you create an index, most storage engines choose the index implementation they will use. For example, InnoDB always uses B-tree indexes. MySQL also uses B-tree indexes, except that it uses R-tree indexes for spatial data types. However, the MEMORY storage engine supports hash indexes and B-tree indexes, and allows you to select which one you want. To choose an index type, consider what kind of comparison operations you plan to perform on the indexed column:
If you use a MEMORY table only for exact-value lookups, a hash index is a good choice. This is the default index type for MEMORY tables, so you need do nothing special. If you need to perform range-based comparisons with a MEMORY table, you should use a B-tree index instead. To specify this type of index, add USING BTREE to your index definition. For example:
CREATE TABLE lookup
(
id INT NOT NULL,
name CHAR(20),
PRIMARY KEY USING BTREE (id)
) ENGINE = MEMORY;
If the types of statements that you expect to execute warrant it, a single MEMORY table can have both hash indexes and B-tree indexes, even on the same column. Some types of comparisons cannot use indexes. If you perform comparisons only by passing column values to a function such as STRCMP(), there is no value in indexing it. The server must evaluate the function value for each row, which precludes use of an index on the column. Use the slow-query log to identify queries that may be performing badly. This log can help you find queries that might benefit from indexing. You can view this log directly (it is written as a text file), or use the mysqldumpslow utility to summarize its contents. (See Chapter 11, "General MySQL Administration," for a discussion of MySQL's log files.) If a given query shows up over and over in the slow-query log, that's a clue you've found a query that might not be written optimally. You may be able to rewrite it to make it run more quickly. Keep in mind when assessing your slow-query log that "slow" is measured in real time, so more queries will show up in the slow-query log on a heavily loaded server than on a lightly loaded one. |
 not a candidate
FROM
tbl1 LEFT JOIN tbl2
ON tbl1.col_b = tbl2.col_c
not a candidate
FROM
tbl1 LEFT JOIN tbl2
ON tbl1.col_b = tbl2.col_c