| only for RuBoard - do not distribute or recompile |
The database tier is the base of a web database application. Understanding system requirements, choosing database-tier software, designing databases, and building the tier are the first steps in successful web database application development. We discuss techniques for modeling system requirements, converting a model into a database, and the principles of database technology in Appendix C. In this section, we focus on the components of the database tier and introduce database software by contrasting it with other techniques for storing data. Chapter 3 covers the standards and software we use in more detail.
In a three-tier architecture application, the database tier manages the data. The data management typically includes storage and retrieval of data, as well as managing updates, allowing simultaneous, or concurrent, access by more than one middle-tier process, providing security, ensuring the integrity of data, and providing support services such as data backup. In many web database applications, these services are provided by a RDBMS system, and the data stored in a relational database.
Managing relational data in the third tier requires complex RDBMS software. Fortunately, most DBMSs are designed so that the software complexities are hidden. To effectively use a DBMS, skills are required to design a database and formulate commands and queries to the DBMS. For most DBMSs, the query language of choice is SQL. An understanding of the underlying architecture of the DBMS is unimportant to most users.
In this book, we use the MySQL RDBMS to manage data. Much like choosing a middle-tier scripting language, there are often arguments about which DBMS is most suited to an application. MySQL has a well-deserved reputation for speed, and it is particularly well designed for applications where retrieval of data is more common than updates and where small, simple updates are the general class of modifications. These are characteristics typical of most web database applications. Also, like PHP and Apache, MySQL is open source software. However, there are down sides to MySQL we'll discuss later in this section.
There are other, nonrelational DBMS software choices for storing data in the database tier. These include search engines, document management systems, and simple gateway services such as email software. Our discussions in this book focus on relational database technology in the database tier.
A database management system stores, searches, and manages data.
A database is a collection of related data. The data stored can be a few entries, or rows, that make up a simple address book of names, addresses, and phone numbers. In contrast, the database can also contain millions of records that describe the catalog, purchases, orders, and payroll of a large company. The database behind our case study, Hugh and Dave's Online Wines, is an example of a medium-sized database that falls between these two extremes.
A DBMS is a set of components for defining, constructing, and manipulating a database. When we refer to a database management system, we generally mean a relational DBMS or RDBMS. Relational databases store and manage relationships between datafor example, customers placing orders, customer orders containing line items, or wineries being part of a wine-growing region.
Figure 1-4 shows the simplified architecture of a typical DBMS.
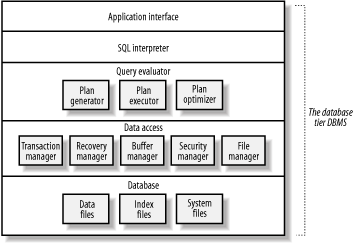
A DBMS consists of several components:
Libraries for communicating with the DBMS. Most DBMSs have a simple command-line interpreter that often uses these libraries to relay requests typed from the keyboard to the DBMS and to display responses. In a web database application, the command-line interpreter is usually replaced by a function library that is part of the middle-tier scripting language.
A parser that checks the syntax of incoming query statements and translates these into an internal representation.
Generates different plans for evaluating a query by considering database statistics and properties, selects one of these plans, and translates the plan into low-level actions that are executed.
The modules that manage access to the data stored on disk, including a transaction manager, a recovery manager, the main-memory buffer manager, data security manager, and the file and access method manager.
The physical data itself stored in data files. The data also contains index files for fast access to data, and database and system summary statistics primarily used for query plan generation and optimization.
The important components for web database application developers are the database and applications interface. For all but large-scale applications, understanding and configuring the other components of a DBMS is usually unnecessary.
A question that is often asked is: why use a complex DBMS to manage data? There are several reasons that can be explained by contrasting a database with a spreadsheet, a simple text file, or a custom-built method of storing data. A few example situations where a DBMS should and should not be used are discussed later in this section.
Take spreadsheets as an example. Spreadsheet worksheets are typically designed for a specific application. If two users store names and addresses, they are likely to organize data in a different waydepending on their needsand develop custom methods to move around and summarize the data. In this scheme, the program and the data aren't independent: moving a column might mean rewriting a macro or formula, while exchanging data between the two users' applications might be complex. In contrast, a DBMS and a database provide data-program independence, where the method for storing the data, the order of the stored information, and how the data is managed on disk are independent of the software that accesses it.
Managing complex relationships is difficult in a spreadsheet or text file. For example, consider our online winestore: if we want to store information about customers, we might allocate a few spreadsheet columns to store each customer's residential address. If we were to add business addresses and postal addresses, we'd need more columns and complex processing to, for example, process a mail-out to customers. If we want to store information about the purchases by our customers, the spreadsheet becomes wider still, and problems start to emerge. For example, it is difficult to determine the maximum number of columns needed to store orders and to design a method to process these for reporting.
Spreadsheets or text files don't work well when there are associations or relationships between stored data items. In contrast, DBMSs are designed to manage complex relational data. DBMSs are also a complete solution: if you use a DBMS, you don't need to design a custom spreadsheet or file solution. The methods that access the datamost often the query language SQLare independent of how the data is physically stored and actually processed.
A DBMS usually permits multiuser transactions. Medium- and large-scale DBMSs include features that control the writing of data by multiple users in a methodical way. In contrast, a spreadsheet should be opened and written only by one user; if another user opens the spreadsheet, she won't see any updates being made at the same time by the first user. At best, a shared spreadsheet or text file permits very limited concurrent access.
An additional benefit of a DBMS is its speed. It isn't totally true to say that a database provides faster searching of data than a spreadsheet or a custom filesystem. In many cases, searching a spreadsheet or a special-purpose file might be perfectly acceptable, or even faster if it is designed carefully and the volume of data is small. However, for managing large amounts of related information, the underlying search structures in a DBMS can permit fast searching, and if information needs are complex, a DBMS should optimize the method of retrieving the data.
There are also other advantages of DBMSs, including data-oriented and user-oriented security, administration software, and data recovery support. A practical benefit is reduced application development time: the system is already built, it needs only data and queries to access the data.
In any of these situations, a DBMS should probably be used to manage data:
There is more than one user who needs to access the data at the same time.
There is at least a moderate amount of data. For example, we may need to maintain information about a few hundred customers.
There are relationships between the stored data items. For example, customers may have any number of related purchase orders.
There is more than one kind of data record. For example, there might be information about customers, orders, inventory, and other data in an online store.
There are constraints that must be rigidly enforced on the data, such as field lengths, field types, uniqueness of customer numbers, and so on.
New or consolidated information must be produced from basic, related information; that is, the data must be queried to produce reports or results.
There is a large amount of data that must be searched quickly.
Security is important. There is a need to enforce rules as to who can access the data.
Adding, deleting, or modifying data is a complex process.
There are some situations where a relational DBMS is probably unnecessary or unsuitable. Here are some examples:
There is one type of data item, and the data isn't searched. For example, if a log entry is written when a user logs in and logs out, appending the entry to the end of a simple text file may be sufficient.
The data-management task is trivial. In this case, the data might be coded into a web script in the middle tier, rather than adding the overhead of a database access each time the data is needed.
The data requires complex analysis. For analysis, a spreadsheet package or statistical software may be more appropriate.
MySQL is a medium-scale DBMS, with most of the features of a large-scale system and the ability to manage very large quantities of data. Its design is ideally suited to managing the databases that are typical of many web database applications.
The difference between MySQL and some other systems is that MySQL is missing some querying support and has limited concurrency-handling abilities. In terms of concurrency, tens of middle-tier processes can access a database at the same time but not hundreds. Two querying techniquesspecifically nested querying and viewsaren't supported, but support is planned for the near future in MySQL Version 4. There are other, more minor limitations that don't typically affect web development.
The limitations of MySQL usually have a very minor impact on web database application development. However, for high-throughput systems, large numbers of concurrent users, or applications that modify the database frequently, other DBMSs may be considered. Our second choice would be PostgreSQL, which is known to be slower but supports more concurrent users. More information on PostgreSQL can be found at http://www.postgresql.org.
At the time of writing, the current version of MySQL is 3.23, and the current release is 3.23.38. MySQL resources are listed in Appendix E.
SQL is the standard relational database interaction language. Almost all relational database systems, including MySQL, support SQL as the tool to create, manage, secure, and query databases. Indeed, this is an important point about SQL: it is much more than just a query language; it is a fully fledged tool for all aspects of database management.
SQL has had a complicated life. It began at the IBM San Jose Research Laboratory in the early 1970s, where it was known as Sequel; some users still call it Sequel, though it's more correctly referred to by the three-letter acronym, SQL. After almost 16 years of development and differing implementations, the standards organizations ANSI and ISO published an SQL standard in 1986. IBM published a different standard one year later!
Since the mid-1980s, three subsequent standards have been published by ANSI and ISO. The first, SQL-89, is the most widely, completely implemented SQL in popular database systems. Many systems implement only some features of the next release, SQL-2 or SQL-92, and almost no systems have implemented the features of the most recently approved standard, SQL-99 or SQL-3.
We focus on features found in the MySQL DBMS. MySQL supports the entry-level SQL-92 standard.
SQL has four major parts, and we discuss two of themthe Data Definition Language (DDL) and the Data Manipulation Language (DML)in detail in Chapter 3. The four major components of SQL are:
DDL is the set of SQL commands that create and delete a database, add and remove tables, create indexes, and modify each of these. DDL commands are generally used only during the construction of the database. Indexes are structures for fast access and updates of data.
DML is the set of commands that work with a DBMS and a database. DML commands include those to search, insert, and delete data. These commands are the tools that interact with a database during its normal use.
SQL includes commands for treating a set of commands as a unit, or transaction. Using these tools, transactions can be undone, or rolled back.
DML and DDL include advanced features for embedding SQL into general-purpose programming languages (in much the same way you can see SQL commands embedded in PHP in Chapter 4) and defining special-purpose views of the underlying data, and granting and removing access rights to the DBMS and databases. They also include commands for ensuring the integrity of the system; that is, ensuring the data is correct and that relational constraints are maintained correctly.
Transaction management and advanced features of SQL are discussed briefly in Chapter 3 and Chapter 6, and in Appendix C. Pointers to references on SQL can be found in Appendix E.
| only for RuBoard - do not distribute or recompile |