9.3. Load BalancingIf we vertically scale, we don't need to worry much about user requeststhey appear at the NIC of our monolithic server, are serviced, and a reply is sent back through the NIC. Spreading load out between the various processors is then the job of the operating system scheduler. Because Apache is multiprocess, we can stick one child on each processor and run many requests in parallel. When we start to scale horizontally, a new problem appears. We have multiple processors, but we have no operating system to spread requests between them. We have multiple requests coming in to the same IP, which we want to service with multiple machines. The solution can come from a number of methods, but they're all grouped under the term "load balancing." The easiest way to load balance between a couple of web servers is to create more than one "A" record in the DNS zone for your application's domain. DNS servers shuffle these records and send them back in a random order to each requesting host. When a user then enters your address into their browser, your browser asks the DNS server (using an iterative query) to return a list of records for that domain. The DNS server replies with the list of addresses and the client starts by trying the first in the list. DNS-based load balancing is by far the easiest way to balance requests between multiple geographical locations, ignoring the issue of redundancy and failover. This is called "poor man's load balancing" for several reasons. Adding or removing any machines from the pool is a slow process. Depending on your zone's TTL and the cache time of DNS servers, it could take up to a couple of days to make a change to the zone that appears for all users. During that time, some users will see the old zone while some will see the new one. If we need to quickly remove a machine, we're out of luck. If a machine dies, we need to find out about it, change the zone, and wait for it to recache everywhere. Anybody hitting that server while it's down may or may not be redirected to a secondary IP address, depending on the behavior of the user's browser. When we detect that a machine is down, it's hard to automate the removal process. We don't want to have it automatically remove it from the DNS zone because any mistake in checking will cause all of the servers to be removed from the IP list, requiring time for the zone to recache after fixing it, during which time the site would be offline completely. The other issue with DNS load balancing is that it can't balance traffic accurately or in a custom configuration (at least, not easily). Because of DNS caching, a user will get stuck on a single machine for an hour or more. If many users share a DNS cache, as in the case with large ISPs, a large portion of your users will get stuck to a single server. DNS load balancing is not a very practical solution. Before we look at better load-balancing solutions, it's worth talking about the two fundamental load-balancing modes and how they differ. For the PHP "shared nothing" application model, each request coming in from a client can be sent to any machine in our pool. This stateless mode doesn't require much from a load balancer because it can treat each request separately and doesn't have to save state. For applications built with shared local data and state, we need to ensure that users hit the same server for every request in a single session (for whatever we define "session" to mean). These "sticky sessions" need to be maintained in the load balancer so that when subsequent requests are made they can be dispatched to the same machine as the initial request. Sticky sessions require more logic and resources from the load balancer, and some load-balancing solutions won't provide these things.
As with every aspect of modern computing, there's at least one three-letter acronym (TLA) you'll need to be familiar withVIP. Short for virtual IP, a VIP is an IP address served by a load balancer with several "real" IPs behind it handling requests. The load balancer is then referred to as a "virtual server," while the nodes in the pool are referred to as "real servers." 9.3.1. Load Balancing with HardwareThe most straightforward way to balance requests between multiple machines in a pool is to use a hardware appliance, however. You plug it in, turn it on, set some basic (or more usually, very complicated) settings, and start serving traffic. There are a couple of downsides to using a hardware appliance. The configurability can be a pain, especially when managing large VIPs (with many real servers) because interfaces tend to either be esoteric telnet-based command-line tools or early 90s web UIs. Any changing or checking of configuration is then a manual process or a journey through writing a set of scripts to operate it remotely by poking its own interfaces. Depending on your scale, this might be not be much of an issue, especially if you're planning to set up the device and just leave it going for a long time. What can be a drawback, however, is the price. Hardware load-balancing devices tend to be very expensive, starting in the tens of thousands of dollars up to the hundreds of thousands. Remembering that we need at least two for disaster failover, this can get pretty expensive. A number of companies make load-balancer products, typically bundled with other features such as web caching, GSLB, HTTPS acceleration, and DOS protection. The larger vendors of such devices are Alteon's AS range (application switches), Citrix Netscalers, Cisco's CSS range (content-switching servers), and Foundry Networks' ServerIron family. Finding these products can initially be quite a challenge due to the ambiguous naming conventions. In addition to being labeled as load balancers, these appliances are variously called web switches, content switches, and content routers. There are several core advantages we gain by using a hardware appliance in preference to the DNS load-balancing method we described earlier. Adding and removing real servers from the VIP happens instantly. As soon as we add a new server, traffic starts flowing to it and, when we remove it, traffic immediately stops (although with sticky sessions this can be a little vague). There's no waiting for propagation as with DNS, since the only device that needs to know about the configuration is the load balancer itself (and its standby counterpart, but configuration changes are typically shared via a dedicated connection). When we put three real servers into a VIP, we know for sure that they're going to get an equal share of traffic. Unlike DNS load balancing, we don't rely on each client getting a different answer from us; all clients access the same address. As far as each client is concerned, there is only one serverthe virtual server. Because we handle balancing at a single point on a request-by-request basis (or by session for sticky sessions), we can balance load equally. In fact, we can balance load however we see fit. If we have one web server that has extra capacity for some reason (maybe more RAM or a bigger processor), then we can give it an unfair share of the traffic, making use of all the resources we have instead of allowing extra capacity to go unused. The biggest advantage of a hardware appliance over DNS-based load balancing is that we can deal well with failure. When a real server in our VIP pool dies, the load balancer can detect this automatically and stop sending traffic to it. In this way, we can completely automate failover for web serving. We add more servers than are needed to the VIP so that when one or two die, the spare capacity in the remaining nodes allows us to carry on as if nothing happenedas far as the user is concerned, nothing did. The question then is how does the appliance know that the real server behind it has failed? Various devices support various custom methods, but all are based on the idea of the appliance periodically testing each real server to check it's still responding. This can include simple network availability using ping, protocol-level checks such as checking a certain string is returned for a given HTTP request, or complex custom notification mechanisms to check internal application health status. 9.3.2. Load Balancing with SoftwareBefore you run out and spend $100,000 on one of these shiny boxes, it's good to know about the alternative. We can do the same sort of load balancing at a software level, using server software running on a regular machine instead of a load-balancing operating system running on an ASIC. Software load-balancing solutions run from simple to super-complex operating systems. We'll look at a couple of common choices and see what they have to offer us. At the simple end of the scale, we have Perlbal (http://www.danga.com/perlbal/), a free Perl-based load-balancing application. Perlbal supports simple HTTP balancing to multiple unweighted backend servers. Connections are only balanced to a server with a working HTTP server, so no configuration is needed to detect and disable dead servers. Runtime statistical information can be obtained easily through the management console interface for monitoring and alerting. Backend servers can be added and removed on the fly, without the need to restart the system. Perlbal does not support sticky sessions. Pound (http://www.apsis.ch/pound/) provides most of the services you'd want from a load balancer. It balances requests between multiple servers, detects failed servers, performs layer 7 balancing (which we'll discuss later in this chapter), supports sticky sessions, and acts as an SSL wrapper. Pound is released under the GPL, so it is free, and it is extremely easy to use. Checking for dead real servers is limited to being able to connect to the web server. There is no way to extract current runtime information from a Pound server to find out which real servers are active at any time, how many requests are being serviced, or any other statistical accounting, which can make debugging tough. Configuration changes require a restart of the daemon program, which can cause lost connections in a high-volume environment. At the complex end of the software spectrum lies the Linux Virtual Server or LVS (http://www.linuxvirtualserver.org/), which adds kernel patches to Linux to turn it into a load-balancing operating system. LVS can redirect traffic using NAT (where replies flow back through the load balancer, as with other software) or using either IP tunneling or direct service routing so that responses go straight from the real servers to the client. The connection scheduling component that selects a real server to service a request comes with no less than 10 scheduling algorithms to allow any mode of real server selection. Sticky sessions are supported using the usual variety of methods (source IP, authentication, URL parameter, cookie, etc.). A huge number of statistics can be extracted at runtime by simply poking the /proc files. All configuration options can be changed on the fly, allowing you to add and remove real servers without any user impact. Several books discuss LVS and its myriad of options, including The Linux Enterprise Cluster by Karl Kopper (No Starch Press), which dedicates a chapter to it. LVS servers can communicate using a heartbeat protocol to allow hot failover if a load balancer dies, making it the only one of our software examples that offers hot failover. If you go down the software load-balancing route, then you'll need to provide hardware for that software to run on. However, the specification of such hardware is usually pretty low so the cost isn't comparable to hardware appliances. Regular boxes are a little more likely to fail than their ASIC-driven counterparts, so having two or more for redundancy is a great idea. If you use the same class of machine for load balancing and web serving, then you can avoid keeping extra spare machines. If you need another load balancer, take a machine from the web server pool and vice versa. 9.3.3. Layer 4Traditionally, load balancing has been a layer 4 (TCP) affair. A layer 4 connection is established and balanced to one of the available real servers. The load balancer only needs to capture the request at this layer since the TCP stream contains all the information we need to route the requestthe source and destination IP address and port. Given this information, we can direct the connection to the correct port at the backend. The simplest form of layer 4 load balancing is using a round robin algorithm. Here we take each incoming connection and direct it to the first listed backend server. When the next request comes in, we direct it to the next backend server and so on until a request has been sent to each of the backend servers. At this point, the next new request is sent to the first backend server and the process starts again. All that's needed at the load balancer level is a list of real servers and a variable to mark the last used server, as shown in Figure 9-2. Figure 9-2. Load balancing at layer 4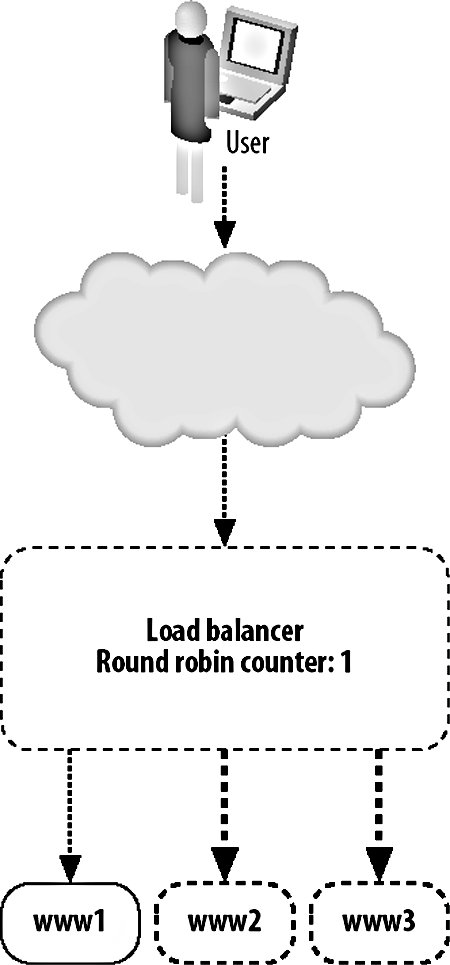 There are other layer 4 scheduling algorithms, but they all work along similar principles, using information about the available real servers and previous or existing connections. In the least connections algorithm, a load balancer checks for active connections (in the case of NAT'ed connections that flow through the balancer) and assigns a new request to the real server currently servicing the least requests. The advantage here over round robin scheduling is that we compensate for real servers that are handling slower queries and don't overload them with too many simultaneous connections. Layer 4 scheduling algorithms also include custom metrics, such as checking the load- or application-specific metric of each real server and assigning new connections based on that. So long as we don't need to look deeper than layer 4 of the request packet, we're said to be a layer 4 balancer. 9.3.4. Layer 7Layer 7 load balancing is a relative newcomer to the party. Layer 7 load balancers inspect the message right up to layer 7, examining the HTTP request itself. This allows us to look at the request and its headers and use those as part of our balancing strategy. We can then balance requests based on information in the query string, in cookies or any header we choose, as well as the regular layer 4 information, including source and destination addresses. The most often used element for layer 7 balancing is the HTTP request URL itself. By balancing based on the URL, we can ensure that all requests for a specific resource go to a single server, as shown in Figure 9-3. Figure 9-3. Load balancing at layer 7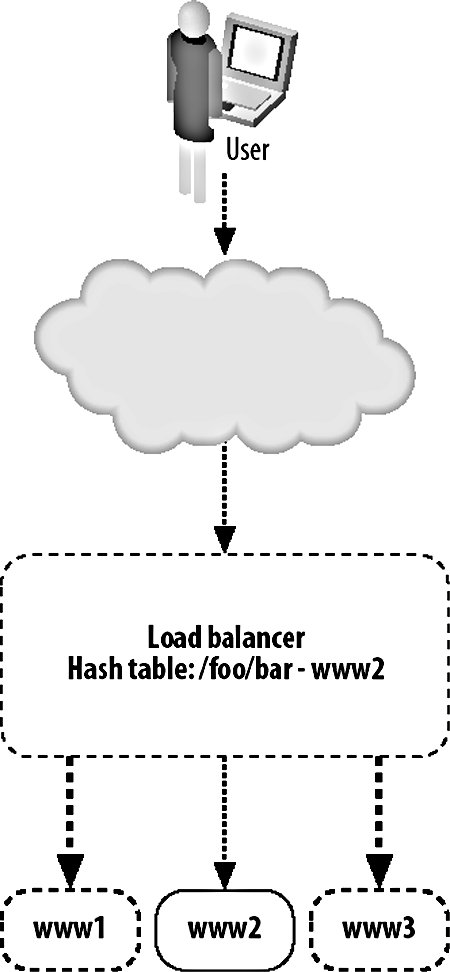 We can do this either by keeping a hash table or by using simple indexing. With a hash table, we create an entry for each URL requested. When a URL is requested that we don't have in our hash, we pick a server for it and store that as its hash value. Subsequent requests for the same URL look in the hash table and find the real server we want to direct the traffic to. Using simple indexing, we can derive a number from the URL by performing some kind of hashing function or CRC on it. If we assign each of the real servers a number, for instance from 1 through 5, then we just need to divide the number of the request modulo the number of servers, add one, and we have the number of the real server to which the URL is mapped. If we use a hashing function that distributes URLs with fairly uniform distribution, then we'll spread an equal number of URLs onto each server. In the case where a real server is unavailable, we need to have some formula to recompute a hash number for one of the remaining real servers. For example, if the URL /foo.txt usually maps to server number 4, but server number 4 is not available, we perform further hash calculations and decide to map the request to server number 2. Any subsequent requests for the same URL will follow the same math and put the URL on the same server. When server 4 is resurrected, requests will start going to that server for the /foo.txt URL again. This approach avoids having to keep a hash table on the load balancer, which means we don't need a lot of RAM or disk. A slight downside is that if server 4 starts to flap, requests will be directed between server 4 and server 2, sticking to neither. By this point, you might be wondering why on earth you'd want to map a particular URL to a particular real server. It's a valid question and the answer isn't always obvious. Imagine the setup shown in Figure 9-4. Figure 9-4. "Load balancer and cache farm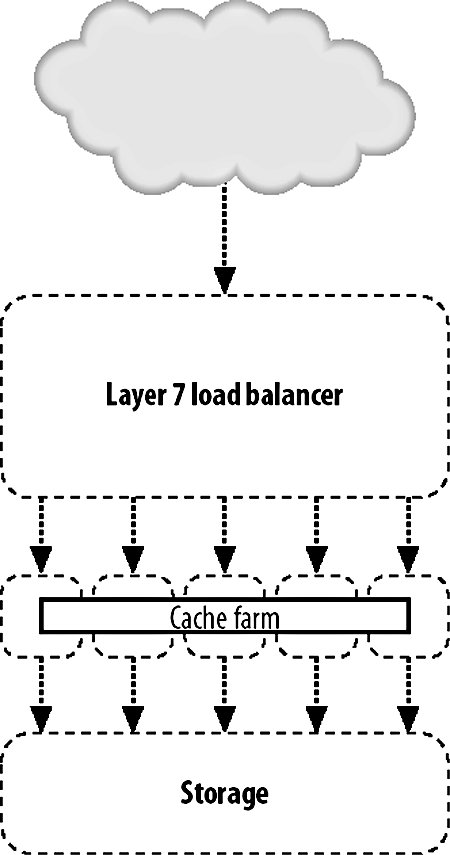 We have some big backing store with files we want to serve. We could serve straight from disk, but disks are slow and we want to get a large number of requests per second, so we use a caching proxy like Squid (which we'll discuss at this end of the chapter) to cache the files we need to serve. Once the working set of files grows to be large, we might want to add another cache server or many more cache servers to handle the load. The cache servers make things fast by only keeping a small portion of the data in memory and on small, fast disks. If we were using a layer 4 load balancer, then requests would be spread out over all of the cache servers and all would be well. Or would it? If we have a large working set, we're going to be gradually churning things out of the cache or at least the in-memory hot cache. We added more servers because we wanted to increase our online cache size. What we find in practice is that each cache is filled with roughly the same contentthe most requested file has been requested many times, with some of the requests going to the first cache server, some to the second, and so on. This means that even if we have five cache servers, we might not be storing any extra objectsall of our cache servers contain the same thing, wasting space. By using a layer 7 load balancer, we can ensure that a single object only ever exists on one cache server, making sure all of our caches are completely unique (ignoring the failover semantics for when a machine drops out of the pool). This allows us to fully use all of our available cache space and to keep more data cached at once. This pushes up our cache hit ratio and allows us to serve far more requests than before, because fewer objects fall out of cache and force us to go to disk. You can achieve layer 7 load balancing using Apache's mod_rewrite and a little bit of scripting. Setting up an instance of Apache as a load balancer, we can have all requests routed through a script:
RewriteEngine on
RewriteMap balance prg:/var/balance.pl
RewriteLock /var/balance.lock
RewriteRule ^/(.*)$ ${balance:$1} [P,L]
Every request that arrives at the load-balancing Apache instance gets passed on to the /var/balance.pl script, which decides where to balance the request. mod_rewrite then rewrites the URL in proxy mode (the P option). A very simple Perl script can be used to balance based on URL, ignoring whether servers in the pool are up or down:
#!/usr/bin/perl -w
use strict;
use String::CRC;
$|++;
my @servers = qw(cache1 cache2 cache3);
while (<STDIN>) {
my $crc = String::CRC::crc($_, 16);
my $server = $servers[$crc % scalar @servers];
print "http://$server/$_";
}
When Apache is started, the script is executed and is then continuously fed URLs to rewrite. The String::CRC module calculates the cyclic redundancy check value for each URL, which is a very fast process (the module is written in C) and always gives the same results for a given string. We then use the CRC value to pick a server from a list of backend boxes. With a little work, we could hook in a database or cache lookup every few seconds to check the status of backend servers or perform HTTP requests to each server in turn to see if it's available, returning the next server on the list (or using some other algorithm) when the first choice server is down. It's not a good idea to run the proxy as part of one of your backend servers because Apache typically has very "fat" threads and your load balancer will need to keep a thread open for every current request to every backend server. Instead, you can run a minimized instance of Apache, loaded with only the modules you need (mod_rewrite and mod_proxy in this case), making each thread a lot smaller. It's also possible to run the load-balancing proxy on one of the backend servers by running two Apache instances, one on port 80 for load balancing and the other on a different port (such as 81) for content serving. Using Apache as a load balancer has another drawbackthe box becomes a single point failure. To get around this, you could use specialized balancing hardware in front of multiple Apache load balancers, use DNS load balancing between multiple Apache load balancers, or use some kind of smart IP failover software at the operating system level. 9.3.5. Huge-Scale BalancingFor larger setups, we need to go beyond the simple single-load balancer (or active/passive pair). For large applications with very specific application areas, we might want to split the serving of the application into one or more transparent clusters. By using a layer 7 load balancer, we can split the real servers into multiple pools, each handling a specific set of URLs. In this case, we could arrange load balancers in a tree, with the front balancer splitting traffic into clusters, each with its own VIP. Each of these clusters would then be fronted by another load balancer to handle the balancing of request among the identical nodes in the cluster. The need for this kind of load balancer configuration is rare, since we can run the whole setup from a single intelligent load balancer. In some situations with layer 7 load balancing at the cluster level, you may need to split the application into multiple areas, each with its own balancer to avoid running out of space in the hash table. At a large scale, a much more likely occurrence is the need for global server load balancing (GSLB), where we balance load between two or more DCs. GSLB performs a few functions beyond simple round robin load balancing. By using various metrics, we can serve content to users from their nearest DC (where nearest might mean hop count or hop latency), allowing them to get the shortest latency possible. It's not uncommon to house an application in multiple DCs close to your user base. If you have servers in a DC on the east and west coasts of America, one in Europe, and one in East Asia, then your users are never very far from the closest one. Although latency is important, multiple data center load balancing gives us the properties we expected from intra-DC load balancing. The main property that concerns us is detecting and routing traffic around failures. We're protected at the machine level by regular load balancers. If a box fails, the load balancer stops sending traffic to it. By using GSLB, we can do the same thing at the DC levelif a data center goes offline, we can continue serving all traffic out of the remaining data centers, keeping us online and providing a seamless experience for our users. Of course, nothing ever works quite that well, and there are some issues with most GSLB strategies. There are two main methods for GSLB, both of which have their problems. We'll talk about the problems with both and what we can do to address them. The fundamental problem with balancing between data centers is that we can't use a single appliance for the balancing in case the outside link to that appliance breaks. As we've already seen, the DNS system has the ability to add multiple "A" records for a domain, pointing to different IP addresses. In our examples, we'll assume we have two data centers, each with a single load balancer. The load balancers have the VIPs 1.0.0.1 and 2.0.0.1, respectively. In the DNS zone files for myapp.com, we put two IPs for the A record1.0.0.1 and 2.0.0.1. When a client requests the IP address for the domain, we give them the list of two addresses, but in a random order. The client tries the first address and gets through to a DC load balancer where we then balance traffic onto one of our real servers. If a data center goes offline and the IP address becomes unreachable, the client will try the next address in the list, connecting to the load balancer in the other DC. For this to work well, we need the load balancers to understand when the servers behind it are all dead and to then appear dead itself. If the connection between a load balancer and the real servers becomes severed (perhaps a network cable got pulled out or a switch crashed), we want traffic to fail over to the other data center. Alternatively, the load balancer with the failed real servers can balance all connections over to the VIP in the other data center. We can add crude proximity-based DC balancing by handling our DNS requests in a smart way. When a DNS request comes in, we can look at who it came from and figure out which data center is closest for that user. We then return the IP address of the VIP in that data center as the DNS response. As clients in different parts of the world request a DNS resolution for our domain, they get different answers. There are some problems with this approach though. The distance we're measuring to find the closest DC is actually the distance to the local DNS server for the user. This is often in a fairly different location to the user, over 10 hops away. A user using a DNS server in another country will get balanced to a DC in the country of his DNS server, not his host. That's not a huge deal, but there's another showstopper: we can't just return the VIP of the nearest DC since we then lose the ability to failover should the DC go down. To get any kind of redundancy, we need to return multiple IP addresses pointing at different DCs. We could send back an ordered list of IP addresses, but intermediate DNS servers will shuffle the list. We can send back a weighted list, giving more priority to a certain DC by including its IP more than once, but that just increases the probability of clients getting their nearest DC rather than ensuring that they do. We could use a time-to-live (TTL) of zero for our DNS responses and reply with only the DC they should connect to. Then if the DC fails, a new DNS request will return working servers. The problem with that is that some DNS caches and nearly all browsers will cache DNS for anything ranging from an hour (for Internet Explorer) to a week (for some caching DNS servers). The real problem with this approach, however, is that we're not able to balance load effectively. A bit of unlucky DNS caching could result in 80 percent of our traffic going to one DC, while the other lays idle, and there's very little we can do about it. By serving DNS from the DC load balancers, we can mitigate this a little by increasing the number of users we send to the idle DC, but we still only marshal traffic around at a high level, rather than connection by connection. An alternative method of achieving fairly reliable failover in a GSLB situation is to use Internet routing protocols to our advantage. This method requires an autonomous system (AS) number as well as cooperation from your ISP at each DC, which makes it impractical for most people. The premise of the system is fairly simple, rooted in how the Internet usually overcomes failure. We publish our DNS as a single IP address of 1.0.0.1, which is contained by our first AS covering 1.0.0.0/24. We advertise this route from the load balancer in our first DC using BGP. At the same time, we publish the same route from our other data center, but with a higher metric (BGP uses metrics to figure out the best path to use). Traffic flows to the load balancer in the first DC, where it can then be balanced between the real servers in the DC and the other DCs on a per connection basis. When the first DC goes down, the local router notices that it's gone away and notifies other routers using BGP, so that the route gets removed from routing tables. Once the routes have converged, which can take five to ten minutes for some routers, traffic for 1.0.0.1 will get routed to the second DC. The downside here, of course, is that our users will be stranded for the time it takes the routes to converge. With this model, we also don't get the reduced latency of local DCs because all our connections flow through the load balancer in the first DC. We can avoid this by having a site-specific name to tie the user to, such as site2.myapp.com, whose DNS record points straight to the VIP in the second DC. When we first make a request to the first DC, it sees we should be using the second DC based on proximity and sends us an HTTP redirect to the site-specific address. The problem with this approach is that we can't deal with the second site failing since we've been "hard balanced" to it using a static domain name. We can get around this by advertising the route to the second DC from the first DC with a higher metric, mirroring the first system. In the case where we were hard balanced to the second DC and it went down, we'd hit the first DC and be hard balanced to stick to it (site1.myapp.com). Neither method is a perfect solution; some combination of the two might be right for you. High-end hardware load-balancing appliances typically have support for DNS-based site failover and site failover where the load balancer survives. Sometimes it can be easier to offload the hassle of global load balancing and failover to a third party. Akamai's EdgePlatform service (previously called Freeflow) is just for this purpose, providing proximity/latency-based DNS balancing with intelligent site failover; you can find out more at http://www.akamai.com. 9.3.6. Balancing Non-HTTP TrafficIt's not necessarily just HTTP traffic we'll want to balance, but also any other services we offer externally or use internally. The other main service you might be offering to external users is email, with a public DNS MX record pointing to an IP address. Just as with web serving, we can point this record at a load-balanced VIP with multiple machines behind it. Unlike HTTP, we can deal with small outages for mail routing during a DC outage. When a mail server tries to send mail to another server (such as our application) and find it's unreachable, it queues the mail and tries again later. For DNS-based load balancing, we can give the IP address of only the nearest DC and rely on the DNS cache timing out for moving traffic to a new DC when the currently selected DC goes down. In fact, email gives us another failsafe method of DNS load balancing. An MX record in a zone file looks a little like this: MX 5 mx1.myapp.com. MX 10 mx2.myapp.com. MX 15 mx3.myapp.com. We attach a priority to each IP address we list, trying lowest entry first. If the connection fails, we try the next in the list and so on until we find a reachable server. We can load-balance email to geographic data centers using only DNS proximity balancing, and we'll get DC failover semantics for free. We only need to give the closest DC the lowest priority, the second-closest DC the next lowest priority, and so on. Because SMTP is so similar to HTTP (a text-based protocol with MIME headers and bodies), you can generally use HTTP load balancers to balance email traffic. All we need to do is create a new service (in load-balancer speak) listening on port 25 and connect it to our backend real servers. The difference comes with detecting whether the real server is active. Load balancers that can only perform HTTP checks (such as Perlbal) will be unable to balance SMTP trafficit'll look to the balancer as if the HTTP daemon on port 25 is down. For balancing other kinds of traffic, we can cheat by encapsulating it in HTTP messages and using a regular HTTP load balancer. Imagine our application had a service that returned a list of the current user's objects. Initially we might "connect" to this service locally using PHP function calls. As our application grows, we see that the service component has very high CPU requirements and so split it out onto a box of its own, connecting to it via a socket-based protocol of our own devising. When the time comes to split the service onto multiple boxes, we need some way of deciding which of the boxes to connect to for each request. If we change the service to allow requests and responses over HTTP, we simply stick a load balancer in front of the service boxes and connect through a VIP. We remove the balancing logic from the application layer and make it look as if we're always connecting to the same single server. For some services, such as database queries from a pool of servers, load balancing can be annoying to set up, given that we don't use an HTTP-based protocol and switching to one would be a pain. Instead, we can employ a form of cheap load balancing using random shuffling. Imagine we had five database slaves, each of which can service our request equally well. Our goal is to put one-fifth of the queries onto each box and deal with a box failing. If we put the server names in an array, we can simply shuffle the list and pop off a server to use. If we fail to connect to the server, we try the next one in the list until we either find a server that we can connect to or we run out of servers. In PHP we can implement this in a few lines:
function db_connect($hosts, $user, $pass){
shuffle($hosts);
foreach($hosts as $host){
$dbh = @mysql_connect($host, $user, $pass);
if ($dbh){
return $dbh;
}
}
return 0;
}
We are returned either a valid database handle or zero if all database choices failed. Because we randomize the host list each time, we spread queries evenly across all servers. If we want to give more of a share of traffic to a particular server, then we simply include it multiple times in the list of hosts. We can then add special short circuit logic to avoid trying to connect to the same server again after it's failed once during a single request. We can also build in logic to have a primary and secondary set of servers; we only try servers from the secondary pool once we've tried all the primary servers. We can very easily implement this by shuffling two arrays and then concatenating them into a single host list. There are a few advantages to this kind of load-balancing model as opposed to using dedicated hardware or software. First, it's a lot cheaper since we don't need any additional hardware to control the balancing. Second, we can balance any kind of traffic our application can connect to, meaning we don't have to try and squeeze our esoteric protocols into running over HTTP. Of course, there are disadvantages, too. We'll be adding more complexity to our business logic layer, where redundancy operations shouldn't reside. Bad separation leads to confusing and hard to maintain applications, so care should always be taken to separate load-balancing actions from the main business-logic code. We also can't support sticky sessions for users without adding extra logic. If we needed sticky sessions, we could generate a random number, store it in a user cookie, and then use it as a randomizing seed. That way, we can shuffle the host list in the same order each time for a single user. We also rely on being able to detect quickly from code that a service is down. If a server goes down in such a way that it accepts connections but never replies to them, then we'll be stuck waiting for a dead server until we hit our I/O timeout. When a server gets into this state, a portion of clients will still get initially balanced onto it and will have to wait for the I/O timeout before getting pushed onto the next server in the list. |