|
|
< Day Day Up > |
|
7.4 Replication ArchitecturesThough MySQL's replication system is relatively simple compared to some commercial databases, you can use it to build arbitrarily complex architectures that solve a variety of problems. In this section we'll look at some of the more popular and exotic configurations. We'll also review how MySQL's replication design makes this possible. 7.4.1 The Replication RulesBefore looking at the architectures, it helps to understand the basic rules that must be followed in any MySQL replication setup:
The first rule isn't entirely true, but let's assume that it is for right now, and soon enough you'll see why it isn't always necessary. In any case, the rules aren't terribly complex. Those four rules provide quite a bit of flexibility, as the next sections illustrate. 7.4.2 Sample ConfigurationsBuilding on the four rules, let's begin by constructing simple replication configurations and discussing the types of problems they solve. We'll also look at the types of configurations that don't work because they violate the second rule. We'll use the simple configuration as a building block for arbitrarily complex architectures. Each configuration is illustrated in a figure that includes the server ID of each server as well as its role: master, slave, or master/slave. 7.4.2.1 Master with slavesThe most basic replication model, a single master with one or more slaves, is illustrated in Figure 7-1. The master is given server ID 1 and each slave has a different ID. Figure 7-1. Simple master/slave replication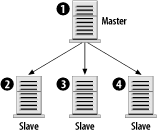 This configuration is useful in situations in which you have few write queries and many reads. Using several slaves, you can effectively spread the workload among many servers. In fact, each of the slaves can be running other services, such as Apache. By following this model, you can scale horizontally with many servers. The only limit you are likely to hit is bandwidth from the master to the slaves. If you have 20 slaves, which each need to pull an average of 500 KB per second, that's a total of 10,000 KB/sec (or nearly 10 Mbits/sec) of bandwidth. A 100-Mbit network should have little trouble with that volume, but if either the rate of updates to the master increases or you significantly increase the number of slaves, you run the risk of saturating even a 100-Mbit network. In this case, you need to consider gigabit network hardware or an alternative replication architecture, such as the pyramid described later. 7.4.2.2 Slave with two mastersIt would be nice to use a single slave to handle two unrelated masters, as seen in Figure 7-2. That allows you to minimize hardware costs and still have a backup server for each master. However, it's a violation of the second rule: a slave can't have two masters. Figure 7-2. A slave can't have two masters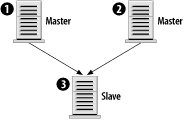 To get around that limitation, you can run two copies of MySQL on the slave machine. Each MySQL instance is responsible for replicating a different master. In fact, there's no reason you couldn't do this for 5 or 10 distinct MySQL masters. As long as the slave has sufficient disk space, I/O, and CPU power to keep up with all the masters, you shouldn't have any problems. 7.4.2.3 Dual masterAnother possibility is to have a pair of masters, as pictured in Figure 7-3. This is particularly useful when two geographically separate parts of an organization need write access to the same shared database. Using a dual-master design means that neither site has to endure the latency associated with a WAN connection. Figure 7-3. Dual master replication Furthermore, WAN connections are more likely to have brief interruptions or outages. When they occur, neither site will be without access to their data, and when the connection returns to normal, both masters will catch up from each other. Of course, there are drawbacks to this setup. Section 7.7.3, later in this chapter, discusses some of the problems associated with a multi-master setup. However, if responsibility for your data is relatively well partitioned (site A writes only to customer records, and site B writes only to contract records) you may not have much to worry about. A logical extension to the dual-master configuration is to add one or more slaves to each master, as pictured in Figure 7-4. This has the same benefits and drawbacks of a dual-master arrangement, but it also inherits the master/slave benefits at each site. With a slave available, there is no single point of failure. The slaves can be used to offload read-intensive queries that don't require the absolutely latest data. Figure 7-4. Dual master replication with slaves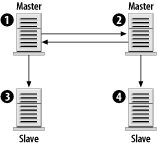 7.4.2.4 Replication ring (multi-master)The dual-master configuration is really just a special case of the master ring configuration, shown in Figure 7-5. In a master ring, there are three or more masters that form a ring. Each server is a slave of one of its neighbors and a master to the other. Figure 7-5. A replication ring or multi-master replication topology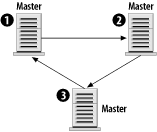 The benefits of a replication ring are, like a dual-master setup, geographical. Each site has a master so it can update the database without incurring high network latencies. However, this convenience comes at a high price. Master rings are fragile; if a single master is unavailable for any reason, the ring is broken. Queries will flow around the ring only until they reach the break. Full service can't be restored until all nodes are online. To mitigate the risk of a single node crashing and interrupting service to the ring, you can add one or more slaves at each site, as shown in Figure 7-6. But this does little to guard against a loss of connectivity. Figure 7-6. A replication ring with slaves at each site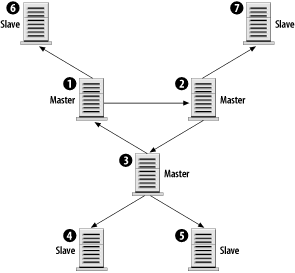 7.4.2.5 PyramidIn large, geographically diverse organizations, there may be a single master that must be replicated to many smaller offices. Rather than configure each slave to contact the master directly, it may be more manageable to use a pyramid design as illustrated in Figure 7-7. Figure 7-7. Using a pyramid of MySQL servers to distribute data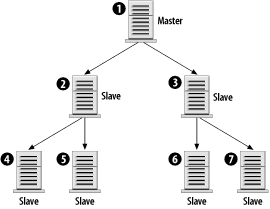 The main office in Chicago can host the master (1). A slave in London (2) might replicate from Chicago and also serve as a local master to slaves in Paris, France (4), and Frankfurt, Germany (5). 7.4.2.6 Design your ownThere's really no limit to the size or complexity of the architectures you can design with MySQL replication. You're far more likely to run into practical limitations such as network bandwidth, management and configuration hassles, etc. Using the simple patterns presented here, you should be able to design a system that meets your needs. And that's what all this really comes down to: if you need to replicate your data to various locations, there's a good chance you can design a good solution using MySQL. You can often combine aspects of the architectures we've looked at. In reality, however, the vast majority of needs are handled with less complicated architectures. As load and traffic grows, the number of servers may increase, but the ways in which they are organized generally doesn't. We'll return to this topic in Chapter 8. |
|
|
< Day Day Up > |
|