|
|
< Day Day Up > |
|
8.1 Load Balancing BasicsFigure 8-1. Typical load-balancing architecture for a read-intensive web site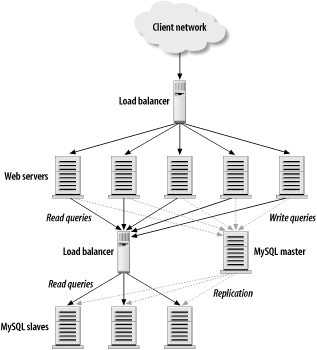 The basic idea behind load balancing is quite simple. You have a farm or cluster of two or more servers, and you'd like them to share the workload as evenly as possible. In addition to the backend servers, a load balancer (often a specialized piece of hardware) handles the work of routing incoming connections to the least busy of the available servers. Figure 8-1 shows a typical load-balancing implementation for a large web site. Note that one load balancer is used for HTTP traffic and another for MySQL traffic. There are four common goals or objectives in load balancing:
Achieving all four goals is critical to providing the type of reliable service that many modern applications demand.
8.1.1 Differences Between MySQL and HTTP Load BalancingIf you're already familiar with HTTP load balancing, you may be tempted to run ahead and set up something similar for MySQL. After all, MySQL is just another TCP-based network service that happens to run on port 3306 rather that port 80, right? While that's true, there are some important differences between HTTP and MySQL's protocol as well as differences between the ways that database servers and web servers tend to be used. 8.1.1.1 RequestsTo begin with, the connect-request-response cycle for MySQL is different. Most web servers and web application servers accept all connections, process a request, respond, and then disconnect almost immediately.[1] They don't perform any fancy authentication. In fact, most don't even bother with a reverse lookup of an inbound IP address. In other words, the process of establishing the connection is very lightweight.
The actual request and response process is typically lightweight too. In many cases, the request is for a static HTML file or an image. In that case, the web server simply reads the file from disk, responds to the client with the data, and logs the request. If the content is dynamic, the PHP, Java, or Perl code that generates it is likely to execute very quickly. The real bottlenecks tend to be the result of waiting on other backend services, such as MySQL or an LDAP server. Sure, there can be poorly designed algorithms that cause the code to execute more slowly, but the bulk of web-based applications tend to have relatively thin business-logic layers. They also tend to push nearly all the data storage and retrieval off to MySQL. Even when there are major differences from request to request, the differences tend to be in the amount of code executed. But that's exactly where you want the extra work to be done. The CPU is far and away the fastest part of the computer. Said another way, when you're dealing with HTTP, all requests are created equalat least compared to a database server. As you saw early on in this book, the biggest bottleneck on a database server usually isn't CPU; it's the disk. Disk I/O is an order of magnitude slower than the CPU, so even occasionally waiting for disk I/O can make a huge difference in performance. A query that uses an index that happens to be cached in memory may take 0.08 seconds to run, while a slightly different query that requires more disk I/O may take 3 seconds to complete. On the database side, not all requests are created equal. Some are far more expensive than others, and the load balancer has no way of knowing which ones are expensive. That means that the load balancer may not be balancing the load as much as it is crudely distributing the load. 8.1.1.2 PartitioningAnother feature that's common in load-balanced web application architectures is a caching system. When users first visit a web site, the web server may assign a session ID to the user, then pull quite a bit of information from a database to construct the user's preferences and profile. Since that can be an expensive operation to perform on every request, the application code caches the data locally on the web servereither on disk or in memoryand reuse it for subsequent visits until the cache expires. To take advantage of the locally cached data, the load balancer is configured to inspect that user's session ID (visible either in the URL or in a site-wide cookie) and use it to decide which backend web server should handle the request. In this way, the load balancer works to send the same user to the same backend server, minimizing the number of times the user's profile must be looked up and cached. Of course, if the server goes offline, the load balancer will select an alternative server for the user. Such a partitioning system eliminates the redundant caching that occurs if the load balancer sent each request to a random backend server each time. Rather than having an effective cache size equal to that of a single server, you end up with an effective cache size equal to the sum of all the backend servers. MySQL's query cache can benefit from such a scheme. If you've dedicated 512 MB of memory on each slave for its query cache, and you have 8 slaves, you can cache up to 4 GB of different data across the cluster. Unfortunately, it's not that easy. MySQL's network protocol doesn't have a way to expose any hints to the load balancer. There are no URL parameters or cookies in which to store a session ID. A solution to this problem is to handle the partitioning of queries at the application level. You can split the 8 servers into 4 clusters of 2 servers each. Then you'd decide, in your application, whether a given query should go to cluster 1, 2, 3, or 4. You'll see more of this shortly. 8.1.1.3 Connection poolingMany applications use connection-pooling techniques; these techniques seem especially popular in the Java world and in PHP using persistent connections via mysql_pconnect( ). While connection pooling works rather well under normal conditions, it doesn't always scale well under load because it breaks one of the basic assumptions behind load balancing. With connection pooling, each client maintains a fixed or variable number of connections to one or more database servers. Rather than disconnecting and discarding the connection when a session is complete, the connection is placed back into a share pool so that it can be reused later. Load balancing works best when clients connect and disconnect frequently. That gives the load balancer the best chance of spreading the load evenly; otherwise the transparency is lost. Imagine you have a group of 16 web servers and 4 MySQL servers. Your web site becomes very busy, and the MySQL servers begin to get bogged down, so you add 2 more servers to the cluster. But your application uses connection pooling, so the requests continue to go to the 4 overworked servers while the 2 new ones sit idle. In effect, connection pooling (or persistent connections) work against load balancing. It's possible to compromise between the two if you have a connection-pooling system that allows the size of the pool to change as the demand increases and decreases. Also, by setting timeouts relatively low (say, five minutes instead of six hours), you can still achieve a level of load balancing while taking advantage of persistent database connections. You can also enforce this on the MySQL side by setting each server's wait_timeout to a relatively low number. (This value tells MySQL how long a connection may remain idle before it is disconnected.) Doing so encourages sessions to be reestablished when needed, but the negative affects on the application side are minimal. Most MySQL APIs allow for automatic reconnection to the server any time you attempt to reuse a closed connection. If you make this change, consider also adjusting the thread_cache as described in Section 6.4.4 in Chapter 6. We don't mean to paint connection pooling in a negative light. It certainly has its uses. Every worthwhile Java application server provides some form of connection pooling. As mentioned earlier, some provide their own load-balancing or clustering mechanisms as well. In such systems, connection pooling combined with load balancing is a fine solution because there's a single authority mediating the traffic to the database servers. In the PHP and mysql_pconnect( ) world, there often is not.
|
|
|
< Day Day Up > |
|