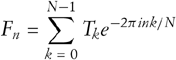So far we have provided an overview on how to detect different types of honeypots. The detection methods usually exploit measurable discrepancies to real systems. In the simple case, these are devices associated with well-known virtual machine solutions like VMware, but the one theme that seems universally problematic is timing discrepancies. No matter what we do, logging overhead or virtualization always has a measurable overhead. An adversary who has a deep understanding of honeypot technology is better equipped to detect the more subtle performance differences. Earlier we have seen that virtualization faces inherent performance problems when trying to simulate guest privileges while running in an unprivileged execution mode. We mentioned that shadow PCI registers might take a single cycle to read, even though real hardware access to the register should take much longer. Similar performance problems exist for any operation that causes hidden page faults in the virtual machine monitor. An adversary who knows that memory-mapped I/O is simulated via hidden page faults has an easy venue to measure timing discrepancies. Similarly, if we suspected that we were running on a honeypot with a rootkit like Sebek, we could trigger behavior that puts Sebek in the code path and measures the increased execution times that way.
Jan K. Rutkowski has presented a principled solution for detecting kernel-based rootkits in Phrack 59. His approach is called execution path analysis (EPA) and is based on counting the number of executed instructions during a system call [75]. It is important to understand that Rutkowski is not trying to detect honeypots, but he is tackling the problem of detecting rootkits. From our point of view, honeypots and rootkits are two sides of the same coin. A rootkit subverts the kernel to spy on regular users, whereas a honeypot might subvert the kernel to spy on adversaries.
Let's take a step back. Why is detecting rootkits a difficult problem? Rootkits try to stay hidden and go to great lengths to make their detection and removal difficult. The simplest approach to subvert the kernel is to install a loadable kernel module (LKM). But even when LKM support has been disabled, clever adversaries can still corrupt the kernel by rewriting its memory on the fly. This might involve disabling the functionalities we might use for detecting changes in a system. Without going into further detail, a rootkit might leave the memory, filesystem, and process table completely unchanged.
To deal with this problem and make progress on detecting rootkits, Rutkowski made the following assumption:
A rootkit extends the functionality of the kernel to spy on users. As a result, some operations are going to lead to longer code paths and more executed instructions than normal.
For example, rootkits often hide their presence in the filesystem. This means that if we call the function set_getdents to get the entries for a directory, the rootkit might intervene to hide its own files and as a result increase the instruction count. To measure how many processor instructions are being executed as a result of a system call, we place the processor into single-step mode when it enters a system call. In single-step mode, the processor is going to raise a debug exception after each executed instruction. To do so, we hook the syscall handler (int 0x80) and the debug exception handler (int 1) in the IDT (Interrupt Description Table). When a system call is initiated, our handler is called. We then enable single-step mode by setting the TF bit (mask 0x100) in EFLAGS register and count the number of times our debug exception handler is called. Although Rutokowski implemented EPA on Linux first, this method has also been realized under Windows. This was a little more difficult, since Windows provides better protection of the IDT. Once it is possible to count the number of executions during a system call, it is possible to build profiles of a clean system.
For example, Rutkowski found that on a clean system, the system calls following the profile shown in Figure 9.5. However, on a compromised system with an installed rootkit, the instruction count profile can look quite different. This is shown in Figure 9.6.
Unfortunately, EPA requires high privileges to access kernel address space and modifications to the system call table are easily detected. Instead of using EPA, G. Delalleau, a member of the French Honeynet Project, suggested detecting the changes in execution time by employing performance counters or instructions provided by the CPU — for example, rdtsc on x86-based hardware. The main problem with this approach is that measurements can vary greatly due to context switches or interrupts. This measurement noise can be counteracted by choosing the mean time or looking at the minimal execution time across multiple measurements.
To make comparisons based on these measurements more accurate, Delalleau proposed the following approach [20]:
Delalleau showed that this worked quite well for the rootkits he tested. For example, this method can be used to detect Sebek by applying it to the read() system call. On a system without Sebek, minimal time is around 8225, and the scalar product is 0.776282. In contrast to this, a system with Sebek has minimal time of 29999 and scalar product of 0.009930. The number of instructions for read() on Sebek is probably so much longer because each read() operation results in sending at least one UDP packet.
Although using Fourier transforms is a clever way of extracting different frequency modes of a measured time series, this particular way of detection needs to be tested much more carefully before it can be used reliably in practice. For example, a normal system, when busy with network traffic, might exhibit similar behavior as a Sebek system that is otherwise idle.