9.6. MySQL ReplicationWe know that having a single MySQL server will only get us so far before we need extra capacity. Web applications typically need a lot more read capacity than write, performing somewhere between 10 and 100 reads for every write operation. To help us scale reads, MySQL has support for replication. Replication is exactly what it sounds likedata is replicated between multiple machines, giving us multiple points to read from. The various modes of replication we'll discuss in a moment all allow us to expand our read capacity over multiple machines by keeping multiple replicas of the table data on multiple machines. In MySQL, replication happens between a master and a slave. Each MySQL instance can be a slave of exactly one master (or not a slave at all) and a master to zero or more slaves. Let's look at each of the main configurations and their relative benefits. 9.6.1. Master-Slave ReplicationMoving from a single server, the simplest configuration to move to is a single master/slave setup, shown in Figure 9-6. Figure 9-6. Master and slave in service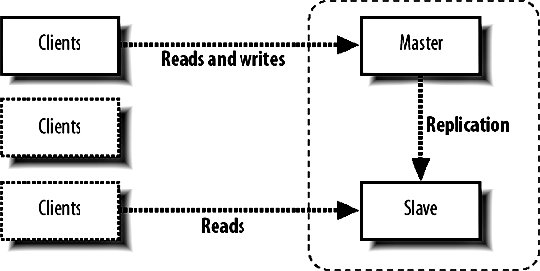 Your previous sole machine becomes the new master server. All the write operations inserts, updates deletes and administrative commands such as creates and altersare performed on the master. As the master completes operations (or transactions, if it's InnoDB), it writes them to a logfile called the binary log (or binlog). When the slave starts up, it connects to the master and keeps the connection open. As events are written to the master's binlog, they get transmitted down to the slave, which writes them into a relay log. This connection is called the replication I/O thread at the slave end and a slave thread at the master end. The slave has a second thread always active called the slave SQL thread. This thread reads events from the relay log (being written by the I/O thread) and executes them sequentially. By copying the events performed on the master, the dataset on the slave gets modified in exactly the same way as the master. The slave can then be used for reading data, since it has a consistent copy of the contents on the master. The slave cannot be written to and should be connected to using a read-only account. Any changes written to the slave do not get replicated back to the master, so your dataset will become inconsistent should you ever write to a slave (this can actually be useful, as we'll see in a moment). Transactions are not replicated as transactions. If a transaction is rolled back, nothing is written to the binlog. If a transaction is committed, each statement in the transaction is written to the binlog in order. This means that for a short time while executing the writes that comprised a transaction, the slave doesn't have transactional integrity. What it does get us is more read power. We should now be able to perform double the amount of readshalf on the master and half on the slave. Both machines still have to perform every write operation (although the master also has to perform rollbacks on failed transactions), so the slave will provide no more read capacity than the master if using the same hardware and configuration. This is a fairly important point that some people misssince your slave needs to perform all the writes the master does, the slave should be at least as powerful as the master, if not more powerful. When we need additional read capacity, we can add more slaves to the master, as shown in Figure 9-7. Figure 9-7. Adding extra slaves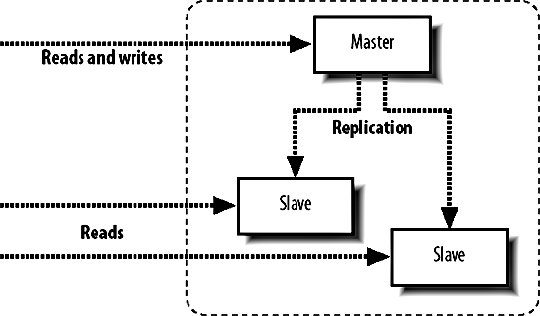 Each slave has its own I/O and SQL threads, relaying the binlog from the master simultaneously. Slaves aren't guaranteed to be in sync with each other as a faster machine (or one serving less reads) will be able to execute writes faster than its siblings. The master keeps one thread open for each connected slave, streaming binlog events as they occur. As your need for read capacity grows, you can keep adding slaves. Some large web applications have literally hundreds of slaves per master, giving amazing read performance with little effort. Using this simple technique, we can scale our read capacity for a very long time. The only problem is that every box has to perform every write, so we can't scale our write capacity. Replication unfortunately can't help us with that, but there are other techniques we'll be looking at later in this chapter which can help. 9.6.2. Tree ReplicationBeyond a simple master with slaves setup, we can create a replication tree by turning some slaves into a master for further machines, shown in Figure 9-8. Figure 9-8. Turning a slave into a master slave.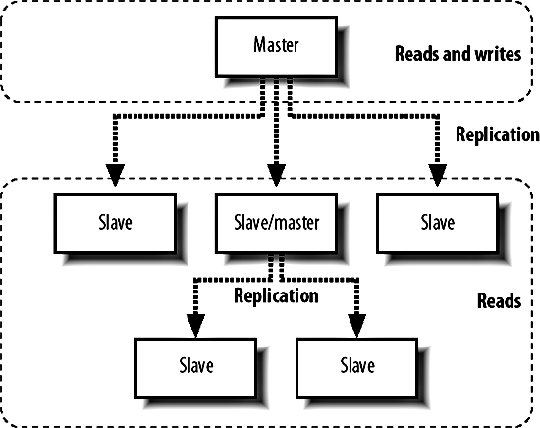 If you have literally hundreds of slaves, the bandwidth required by the master to replicate to all slaves becomes substantial because each slave requires a unicast notification of each event, all coming from a single NIC on the master (we could bond multiple NICs together or use subnetting, but that's beside the point). Each slave requires a thread on the master and at some point the thread management and context switching involved becomes a significant load. We can limit the number of slaves talking to any single master by turning some of those slaves into master of further slaves. If we limit ourselves to 100 slaves per master, we can accommodate 1 + 100 + (100 X 100) machines in a three-level tree; that's 10,101 machines. Going just one level deeper, we can have 1,010,101 machines. We'll have more machines than we possibly need before we get very deep at all. There are downsides to this approach, however. If a middle-tier slave goes down, the slaves beneath it will stop replicating and go stale. We'll discuss the redundancy problems with replication shortly, but this is clearly not a desirable situation. Each write event will also take longer to hit the bottom-tier slaves. A write first gets performed on the top-level master and then relayed and queued for execution on the second-level slaves. Once executed on a second-level slave, it gets relayed and queued for execution on the third-level slave. The third-level slave has to wait for not only its own event queue, but also that of its own master. On the plus side, we can do some other pretty cool things with multitier replication. MySQL allows us to include or exclude database and tables by name from the replication stream, allowing us to replicate only a portion of data from a master to a slave, as shown in Figure 9-9. Figure 9-9. Replicating portions of information to reduce data traffic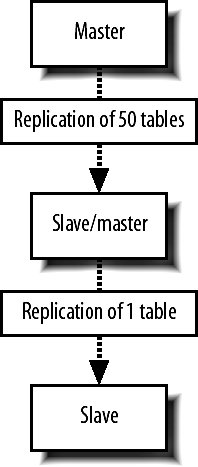 If we perform a write query directly on to a slave, the write doesn't get replicated up to its masterwe've already said that we should connect to slaves using a read-only account to avoid making our data inconsistent. If we make a write to a middle-tier slave, the write is performed on its copy of the data and replicated down to its slaves. We can combine these concepts to create specialized slaves for performing certain tasks. For instance, imagine we use InnoDB for our 50 tables because we need good concurrency for reads and writes. We have a single table that contains user accounts, including a description the user entered of herself. We'd like to be able to perform a full text search of the Users table, which the FULLTEXT index type would be perfect for. However, that's only available for MyISAM tables, and we need to use InnoDBif we switch the Users table to MyISAM, we won't be able to keep up with the rate of inserts and updates we need since the machine is busy with other tables and the Users table has many other indexes, making it slow to update (which is bad if we're locking the table for updates). We can create a branch of slaves that only replicate the Users table, increasing the capacity on our specialized slaves. We can then drop the other indexes on the Users table from the slaves; the slaves will no longer have any indexes on the Users table, but the master and any other slaves hanging from it will be untouched. Because our specialized slaves only handle one table and can perform faster inserts due to the lack of indexes, we can use MyISAM. We issue an alter on the specialized slaves to set the storage engine to MyISAM and only the slaves get changedthe master and other slaves continue using InnoDB, keeping all the original indexes. We can then add a FULLTEXT index on the specialized slaves for searching the user descriptions. Because replication sends its updates as SQL statements, we can replicate from an InnoDB table to a MyISAM table with no problems. The data in the two remains in sync, while the indexes, schema, and engine type can be different. 9.6.3. Master-Master ReplicationTaking a different approach, we can create a pair of servers, each of which is a slave of the other. This is known as master-master replication, shown in Figure 9-10. Figure 9-10. A master-master replication setup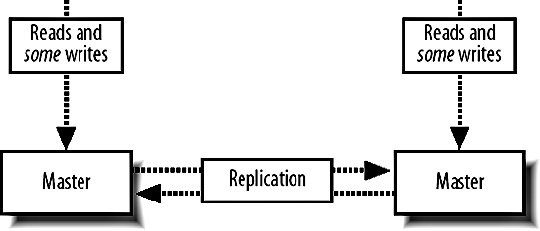 Each server reads the binary logs of the other, but a feature of the replication system avoids a server replaying an event that it generated. If a write happens on server A, it gets replicated to server B and executed, but then doesn't get replicated back to server A. Each server in a replication setup has a unique server ID, which each event in the replication log gets tagged with. When a server encounters a replication event with its own server ID, it simply throws it away. The drawback of the master-master setup is that we can't just write anywhere if we use autoincrementing primary IDs. If we were to insert two different records into the two masters simultaneously, they would both get assigned the same autoincrement ID. When the events got replicated, both of them would fail as they failed to satisfy the primary key constraint. This is clearly not a good situation and replication actually stops and writes to the MySQL error log in this situation, since it's nearly always badif the event executed on the master but failed on the slave, the two must have inconsistent data. We can get around this in a couple of ways. We can partition the code in our application to make writes for some tables to server A and writes for other tables in server B; this means we can still use autoincrement IDs and will never collide. We can also avoid using autoincrement fields as keys. This is simple because we have other columns in the table that contain unique values, but typically for our first class object tables (such as user accounts), we won't have anything that's suitable (email addresses and usernames aren't as indexable as numbers, take up a lot more spaces, and would have to be used as a foreign key in other tablesick). We can get around this by using some other service for generating unique IDs, but we'll need to relax the reliance on the IDs being sequential. For record ordering based on insert order, we'll need to have timestamps on each record, since there is no true "order" to the inserts. Both servers have their own idea of what constitutes the correct order. We can expand the pair of master servers by considering it as a two-machine ring. We can create rings with any number of servers as long as each machine is a master to the machine after it and a slave of the machine before it, as shown in Figure 9-11. Figure 9-11. Structuring a ring of masters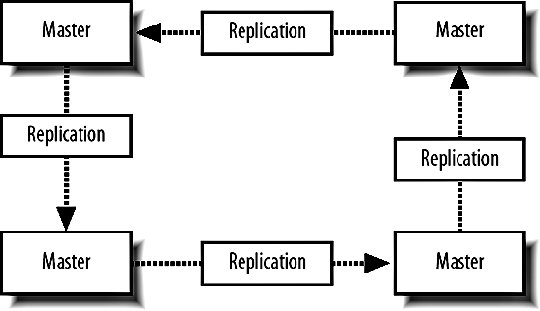 One of the downsides to a multimaster approach is that there's no single "true" copy of the dataat any time the data on all the machines will vary (assuming there's traffic), with some records existing on some portion of servers before they're replicated around. This can make consistent reading a little bit tricky. If you need to know the exact value of a row at any time, you'd have to stop all writes to all machines, wait for replication to catch up, and then perform the read, which is not really practical in a production system. 9.6.4. Replication FailureSo what is a master-master setup good for? Redundancy is the answer heresince each machine is a mirror of the other and is geared up to take writes, we can failover to either machine when the other fails. Assuming we're not using autoincrementing IDs, we can write any record to any machine at any time. We can then balance writes similarly to the way we balance reads, by trying the first machine in a list and trying again until we find an active server. The trick here is to stick a user to a single machine for a single session (unless it goes down) so that any reads will get a consistent version of the data in relation to any writes performed by the user. Redundancy isn't as clear-cut with a master ring. While we can write to any of the machines, a failure in a single machine will cause all machines after it in the chain (with the exception of the machine just behind it) to become stale, as shown in Figure 9-12. Figure 9-12. Failure in one machine makes others stale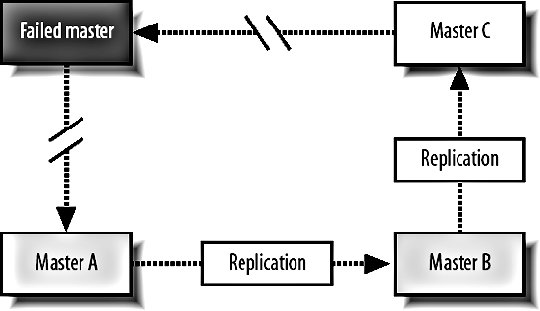 Writes can still be performed on machines A, B, and C, but writes to B won't be replicated to A, while writes to C won't be replicated anywhere. Only machine C will have all writes replicated to it, so it is the only nonstale machine until the failed master is resurrected. The master-master setup is the only one that gives us clear failover semantics, but can't offer more than two machines in a single cluster. We can extend the setup somewhat by adding one or more slaves to each master, giving us more read power as well as write redundancy, as shown in Figure 9-13. Figure 9-13. Adding slaves to help read power and redundancy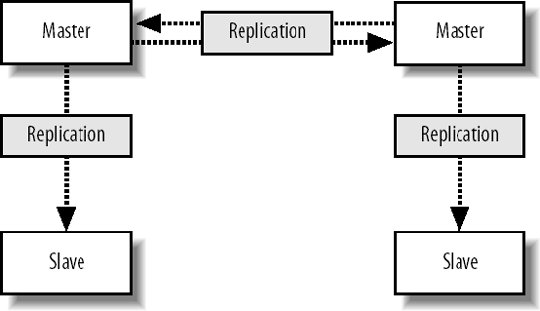 However, if a master fails, all the slaves under it become stale. We can deal with this in the application by only connecting to slaves of a master we've already connected to in this session. Unfortunately, this means that we need twice as many slaves as are required to handle the load so that when a master and its slaves fail we can continue serving all traffic from the remaining master and slaves. Any of the other models give us string redundancy for reads, but no redundancy at all for writesif the master fails, we can no longer write to the cluster. For setups where we need further redundancy, we need to look outside of the replication system to other methods. 9.6.5. Replication LagWe've touched on the issue of replication lag, but haven't really addressed it so far. Replication lag is the time it takes for an event executed on the master to be executed on a slave. For an otherwise idle system, this is usually in the order of milliseconds, but as network traffic increases, and the slave becomes loaded with reads, events can take some time to reach the slaves. In the case where replication is lagging, we can easily end up with stale reads, as shown in Figure 9-14. Figure 9-14. Stale data caused by slow replication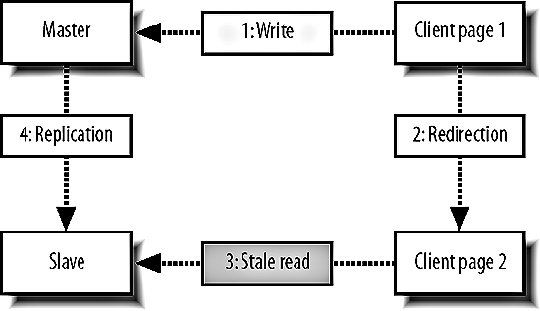 A user submits a form somewhere in our application, and we perform a write on the master. We then redirect the user to see the results of his submission and read from the slave. If this read happens too soon after the write, the write may not have replicated to the slave, so we read stale data. To users, this manifests itself as changes disappearing after they're made. The default user behavior then tends to perform the action again, causing another write and read. While the read might be stale, it might also have caught up to the previous write. This user behavior makes the problem worse, as it increases the read and write load-causing a vicious circle where load spirals up. We can address this in a couple of ways: either we use synchronous replication (where we have to perform the write to all servers before continuing) or we reduce load so that replication is always fast. The former requires either a special database technology (such as MySQL 5's NDB, which we'll talk about shortly) or a technology we write ourselves (which we'll also talk about toward the end of this chapter). Along with query rates and general machine statistics, replication lag is a very important statistic to monitor and we'll be looking at various methods for tracking it in Chapter 10. |