9.7. Database PartitioningTo allow our database to scale writes as well as reads, we need to start chopping it up into chunks as we do with web serving. Each piece we chop it up into will be able to handle the same number of writes as our initial single monolithic database, doubling our write capacity each time we double the number of chunks. We can chop our data up in two ways, which are confusingly referred to as horizontal and vertical partitioning. Vertical partitioning, known as clustering, allows for easy but limiting scaling, while horizontal partitioning is a good general solution, allowing us to scale to any number of chunks but with a lot more effort involved. We'll look at the how we can implement each of them and the associated benefits and drawbacks they bring. 9.7.1. ClusteringClustering is known as vertical partitioning because of its limited scope for growth, although that's where the similarity ends. As with horizontal scaling, clustering involves splitting your database into multiple chunks or clusters, each of which contains a subset of all your tables, as shown in Figure 9-15. Figure 9-15. Splitting data across clusters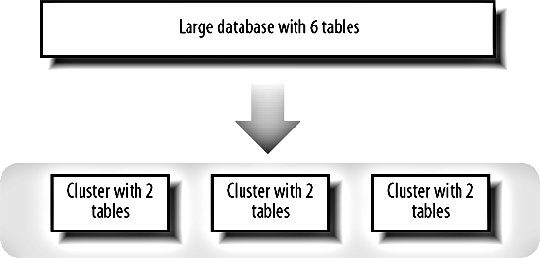 This typically involves a large amount of application change, although the changes are fairly rote. By identifying which queries operate on which tables, we can modify our database dispatching layer to pick the right cluster of machines depending on the tables being queried. Each cluster can then be structured however you wisha single machine, a master with slaves, or a master-master pair. Different clusters can use different models to suit the needs of the various tables they support. To start splitting a large application database down into multiple clusters, you first need to list out all the tables you have. This is trivial with the SHOW TABLES command: mysql> SHOW TABLES; +-----------------+ | Tables_in_myapp | +-----------------+ | Frobs | | Payments | | Replies | | Topics | | Users | | Widgets | +-----------------+ 6 rows in set (0.00 sec) The next part is a little harderwe need to go through every SQL query in our source code and figure out which tables are joined with each other. We can't split joined tables out into different clusters unless we can modify our application logic to avoid making the join. We then end up with a list of possible clusters and the tables they would contain: Cluster 1: Payments, Users Cluster 2: Replies, Topics Cluster 3: Frobs Cluster 4: Widgets We don't have to split all of these up straight awaywe can simply carve off as much as we need with our current hardware setup. We might initially choose to separate the single database into two clusters, the first containing table clusters 1 and 3 while the second cluster contains table clusters 2 and 4. When we then need to expand capacity again, we can split into three or four clusters. When we've hit our four clusters in our example application, we can no longer split any further. This limitation of clustering means that if we have a single table or set of joined tables with many writes, we're always bound by the power of a single server. There are other downsides to this approach. Management of the clusters is more difficult than a single database, as different machines now carry different datasets and have different requirements. As we add any components that are not identical, the management costs increases. Each page in our application that needs to use several tables will need to establish several MySQL connections. As the number of clusters increases, the connection overhead increases. By splitting tables into clusters, we also don't increase our connection limit. If a single master allows 200 connections before slowing down, then by having two clusters, we'll have 400 master connections. Unfortunately, since each page needs to connect to both clusters, we use twice as many connections, thus negating the gain. If a single large table requires many simultaneous connections, clustering doesn't help us. 9.7.2. FederationFederation is the horizontal scaling equivalent for databases. To be able to scale out to arbitrary sizes, we need to be able to just add hardware to increase both read and write capacity. To do this for large tables, we need to be able to slice the data in the table up into arbitrarily sized chunks. As the size of our dataset and the number of queries we need to execute against it changes, we can increase the number of chunks, always keeping the same amount of data and same query rate on each chunk. These chunks of data and the machines that power them are usually referred to as shards or cells, but are sometime called clusters (just to make things confusing). MySQL 5's NDB storage engine tries to do something like this internally without you having to change any of your application logic. For the moment, NDB is not really usable in a high-traffic production environment but this may change fairly soon. Going down the non-MySQL route, Oracle's RAC (Real Application Clusters) software offers similar capabilities, but is a little pricey. At $25,000 per processor licensing, 20 dual processor servers will set you back a million dollars after the cost of the hardware. As you need to scale further, this can become a serious expense. SQL server also offers something similar, but is relatively slow on the same hardware and can cost up to $30,000 per processor. In addition, you'll need to be running Windows, which adds additional costs and management issues that you'd be wise to avoid. Performing federation yourself is difficult. Selecting a range of data from a table that has been split across multiple servers becomes multiple fetches with a merge and sort operation. Joins between federated tables become impossibly complicated. This is certainly true for the general case, but if we design our application carefully and avoid the need for cross-shard selects and joins, we can avoid these pitfalls. The key to avoiding cross-shard queries is to federate your data in such as way that all the records you need to fetch together reside on the same shard. If you need to show a user all of their frobs on a page, then we can slice up the frobs table by user, putting the frobs for one chunk of users on one shard, another chunk on another, and so on. We then store the shard ID in the user's account record so that we know exactly where to look for the user's frobs when we need to. If we also need another view onto the same data, such as all green frobs belonging to any users, then we'll need to carve the data up in that way too. The way to accomplish this is our friend denormalization: we'll have our normalized table "Frobs," which is carved up by user, and a denormalized table "FrobsByColor," which is carved up by color. We need to store twice as much data, but we can create any number of shards we want, keeping the record count on each shard low. Keeping this denormalization and shard access logic in our application logic layer can make for complicated code and make mistakes more likely. To mitigate this, we can split the federation logic into its own conceptual layer, shown in Figure 9-16. Figure 9-16. Separating federation logic into a separate layer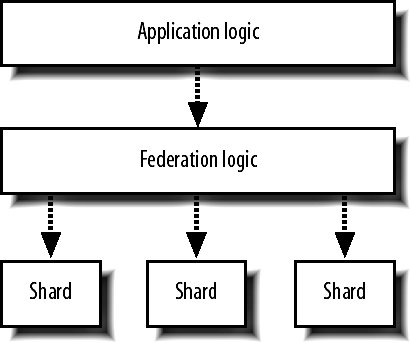 By creating this data access middleware, we can keep all shard and denormalization logic in one place, making it simpler and less error prone. When we need to get a list of frobs, we pass our user ID to the middleware. The middleware knows what shard contains the user's frobs, so it passes the query on and returns the result set to the application layer. The application doesn't need to know how many shards there are, how the data is split across them, or what shard a user is assigned to. We just make a request for the data we want and the storage layer does the magic. One of the often-criticized elements of denormalizing data over multiple machines is that we can easily end up with inconsistent data due to the lack of transactional integrity. We can't guarantee transactional integrity because we're writing to two machines, either of which could crash during the operation. We can get a little closer to avoiding inconsistency by using a pair of transactions to handle our writes. For example, we need to write a record to the Frobs tables on server A and the FrobsByColor table on server B. We start by opening a transaction on server A and executing the change, but we don't commit it. We then open a transaction on server B, execute the change, and commit it. Finally, we commit the first transaction. If the first server has failed before we started, we would try other servers in the same shard or abort the whole process. If the second server had failed, we could try other servers in its shard or roll back the first open transaction and abort the whole process. The only danger lies in server A dying in the time between our committing the second and first (still uncommitted) transactions. This isn't perfectby using a pair of transactions in this way we can cut the danger window down to a couple of milliseconds and avoid the much larger problem of one of the shards being down when we start the process. When we have multiple shards, we need a new set of tools to administer them. We'll need to build tools for shard-specific management tasks, such as checking that the schema on each shard is consistent and that each machine in each shard is getting utilized efficiently. Part of your shard management toolkit should be tools to help you add and remove additional shards. As you grow, the time will come when you need to add shards. Adding new shards and making them available for writing new objects (such as new users, by which you'll federate data) is all very well, but that doesn't allow us to take advantage of new hardware as soon as we bring it onlineonly a small portion of our dataset will reside on new shards. At the same time, this doesn't give us the ability to scale when a shard becomes overloaded (such as when the users on that shard increase their datasets over time), so we end up with early shards being overutilized while newer shards are underutilized. If we build in the ability to move objects between shards, we can migrate data as new shards arrive and old shards become heavily loaded. For doing this, we'll need to build a tool to move the records federated by a particular primary key (say, a user ID) from shard to shard. With this, we can selectively migrate portions of data between shards, using the optimal amount of capacity on each. |